手把手教学:基于 Gemini Multimodal Live API 构建低延迟音视频 AI 助理
说实话,当我第一次听说 Gemini 出了一个 Live API 的时候,心里还挺犯嘀咕的——又是个新 API,会不会跟之前那些文本接口差不多?但当我真正上手试了一把之后,怎么说呢,感觉像是打开了新世界的大门。今天我就来跟大家分享一下,怎么用这套 API 搭建一个真正能实时对话的 AI 助手。
什么是 Gemini Multimodal Live API?
我们先把事情说清楚。传统的 Gemini API 是怎么工作的呢?你发一段文字过去,它回一段文字,简单直接。但如果你想做语音交互,就得自己接 ASR(语音识别)和 TTS(语音合成),中间转来转去,延迟一下子就上去了。
Gemini Multimodal Live API 不一样的地方在于——它原生就支持音频输入输出。也就是说,你的麦克风采集到的声音可以直接扔给它,它返回的也是纯音频流,不需要你在中间搞什么格式转换。这种端到端的架构设计,直接把延迟压到了 500ms 以内。
我在做一个智能家居项目的时候试过这个功能。用户说”把客厅灯调暗一点”,AI 几乎是在话音刚落的时候就给出了回应,那种流畅感真的会让人忘记对面是个程序。
目前支持的模型是 gemini-2.0-flash-native-audio-preview,注意这个版本号,Google 还在快速迭代中,建议定期关注更新。
架构设计与技术选型
好,现在我们来聊聊怎么搭这个系统。我的建议是前后端分离的架构,原因很简单:API Key 不能暴露在前端。
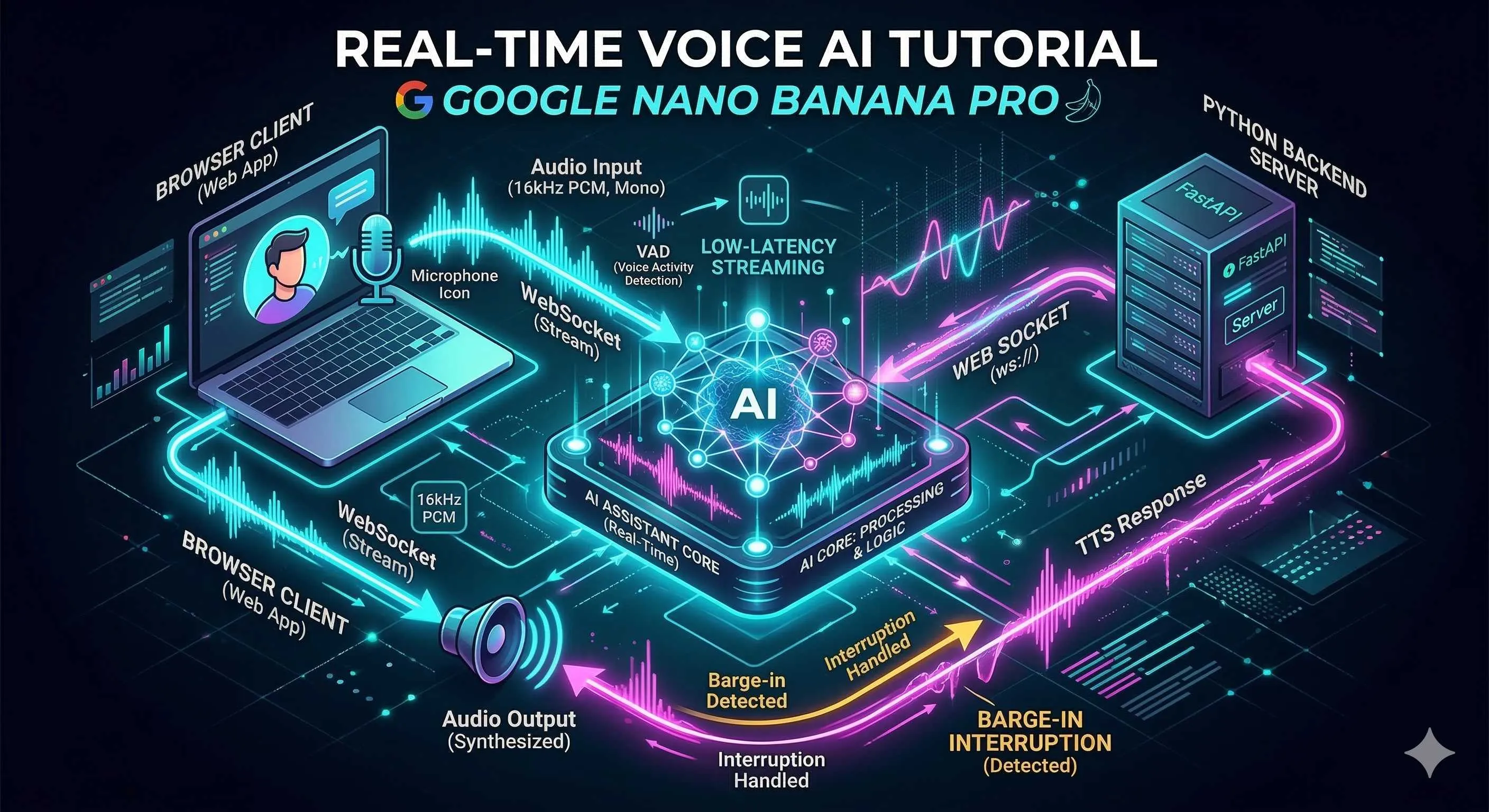
整体的数据流是这样的:
[浏览器] --WebSocket--> [Python后端代理] --WebSocket--> [Gemini Live API]
| | |
麦克风采集 中转+业务逻辑 AI处理
扬声器播放 VAD检测/插话控制 音频生成你可能会想,为什么不能直接让浏览器连 Gemini 呢?技术上是可以的,但这就意味着要把 API Key 写在 JavaScript 里,随便一个人打开开发者工具就能拿到你的密钥。这种事我干过一回,第二天账单就炸了,教训深刻。
所以我们的技术栈是这样定的:
| 层级 | 技术 | 用途 |
|---|---|---|
| 前端 | 原生 JavaScript + Web Audio API | 音频采集、播放、AudioWorklet 实时处理 |
| 后端 | Python 3.9+ + websockets 库 | WebSocket 代理、VAD 检测、会话管理 |
| 协议 | WebSocket + JSON | 与 Gemini 的双向通信 |
Web Audio API 里的 AudioWorklet 是个好东西,它可以在独立的线程里处理音频,不会阻塞主线程。后面我会给出具体的实现代码。
WebSocket 连接建立与会话管理
好了,现在开始写代码。首先要解决的是怎么连上 Gemini 的服务。
Live API 的 WebSocket 端点长这样:
wss://generativelanguage.googleapis.com/ws/google.ai.generativelanguage.v1alpha.GenerativeService.BidiGenerateContent?key=YOUR_API_KEY注意那个 v1alpha,说明这还是预览版,接口可能会变,生产环境用的时候要留个心眼。
连接建立之后,第一件事是发送 Setup 消息,告诉 Gemini 你想怎么聊:
import asyncio
import json
import websockets
GEMINI_API_KEY = "your-api-key-here"
GEMINI_WS_URL = (
f"wss://generativelanguage.googleapis.com/ws/"
f"google.ai.generativelanguage.v1alpha.GenerativeService.BidiGenerateContent"
f"?key={GEMINI_API_KEY}"
)
CONFIG = {
"setup": {
"model": "models/gemini-2.0-flash-native-audio-preview",
"generation_config": {
"response_modalities": ["AUDIO"],
"speech_config": {
"voice_config": {
"prebuilt_voice_config": {
"voice_name": "Charon" # 可选: Charon, Aoede, etc.
}
}
}
},
"system_instruction": {
"parts": [{"text": "你是一个 helpful 的 AI 助手,回答简洁自然。"}]
}
}
}
async def connect():
async with websockets.connect(GEMINI_WS_URL) as ws:
# 发送 setup 配置
await ws.send(json.dumps(CONFIG))
# 等待 setup complete 响应
response = await ws.recv()
data = json.loads(response)
if "setupComplete" in data:
print("✅ 连接建立成功,可以开始对话了")
return ws
else:
raise Exception(f"Setup 失败: {data}")这里有几个参数值得说说:
response_modalities: 设成["AUDIO"]表示我们只想要语音回复。如果你也想要文字,可以改成["AUDIO", "TEXT"]voice_name: Gemini 提供了几种预设音色,我自己比较喜欢Charon,听起来比较沉稳
连接断开重连这块,我建议用指数退避策略,别一上来就疯狂重试,容易把服务打挂:
async def connect_with_retry(max_retries=5):
for attempt in range(max_retries):
try:
return await connect()
except Exception as e:
wait_time = min(2 ** attempt, 30) # 最多等30秒
print(f"连接失败 ({e}),{wait_time}秒后重试...")
await asyncio.sleep(wait_time)
raise Exception("多次重试后仍无法连接")16kHz PCM 音频流的采集与传输
好了,连接有了,接下来要解决音频从哪来、怎么送过去的问题。
先说一下为什么选 16kHz。人声的频率范围一般在 85Hz 到 255Hz 之间(男声偏低,女声偏高),按照奈奎斯特采样定理,理论上 8kHz 就够了。但实际上要保留一些细节,16kHz 是个 sweet spot,既保证了音质,又不会让数据量太大。Gemini 官方也是推荐这个采样率。
前端的采集代码是这个样子:
class AudioRecorder {
constructor() {
this.sampleRate = 16000;
this.bufferSize = 1024;
this.audioContext = null;
this.workletNode = null;
this.stream = null;
this.onAudioData = null; // 回调函数
}
async start() {
// 请求麦克风权限
this.stream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: 16000,
channelCount: 1,
echoCancellation: true,
noiseSuppression: true
}
});
// 创建 AudioContext,强制指定采样率
this.audioContext = new AudioContext({
sampleRate: 16000
});
// 加载 AudioWorklet 处理器
await this.audioContext.audioWorklet.addModule('pcm-processor.js');
const source = this.audioContext.createMediaStreamSource(this.stream);
this.workletNode = new AudioWorkletNode(this.audioContext, 'pcm-processor');
// 处理音频数据
this.workletNode.port.onmessage = (event) => {
const float32Data = event.data;
// 转换为 Int16 PCM
const int16Data = this.float32ToInt16(float32Data);
// Base64 编码后发送
const base64Data = btoa(String.fromCharCode(...new Uint8Array(int16Data.buffer)));
if (this.onAudioData) {
this.onAudioData(base64Data);
}
};
source.connect(this.workletNode);
console.log('🎤 音频采集已启动');
}
float32ToInt16(float32Array) {
const int16Array = new Int16Array(float32Array.length);
for (let i = 0; i < float32Array.length; i++) {
// Float32 (-1.0 ~ 1.0) -> Int16 (-32768 ~ 32767)
const s = Math.max(-1, Math.min(1, float32Array[i]));
int16Array[i] = s < 0 ? s * 0x8000 : s * 0x7FFF;
}
return int16Array;
}
stop() {
if (this.workletNode) {
this.workletNode.disconnect();
}
if (this.audioContext) {
this.audioContext.close();
}
if (this.stream) {
this.stream.getTracks().forEach(track => track.stop());
}
console.log('🛑 音频采集已停止');
}
}AudioWorklet 需要单独的文件 pcm-processor.js:
// pcm-processor.js
class PCMProcessor extends AudioWorkletProcessor {
process(inputs, outputs, parameters) {
const input = inputs[0];
if (input && input[0]) {
// 发送给主线程
this.port.postMessage(input[0].slice());
}
return true; // 保持处理器活跃
}
}
registerProcessor('pcm-processor', PCMProcessor);后端收到数据后,要转发给 Gemini:
async def send_audio(ws, base64_pcm_data):
"""将音频数据发送给 Gemini"""
message = {
"realtime_input": {
"media_chunks": [{
"mime_type": "audio/pcm;rate=16000",
"data": base64_pcm_data
}]
}
}
await ws.send(json.dumps(message))这里有个坑我要提醒一下:有些浏览器的 getUserMedia 会忽略你指定的 sampleRate,实际返回的可能是 44.1kHz 或 48kHz。保险起见,最好在 AudioContext 里再 resample 一次,或者干脆用第三方库比如 audiobuffer-to-wav 来处理。
VAD 语音活动检测实现
现在我们面临一个问题:如果不管三七二十一把所有音频都发给 Gemini,那沉默的时候也在传数据,既浪费带宽又浪费钱。这时候就需要 VAD(Voice Activity Detection,语音活动检测)出场了。
VAD 的作用很简单:判断这段音频里有没有人说话。有人说话才发,没人说话就歇着。
我推荐用 Google 开源的 WebRTC VAD,轻量、速度快、效果还不错。Python 有封装好的库 webrtcvad:
import webrtcvad
import collections
import numpy as np
class VADProcessor:
def __init__(self, aggressiveness=2, frame_duration_ms=20):
"""
aggressiveness: 0-3,越高越严格(越容易把语音判成静音)
frame_duration_ms: 10, 20, or 30
"""
self.vad = webrtcvad.Vad(aggressiveness)
self.frame_duration_ms = frame_duration_ms
self.sample_rate = 16000
# 用于平滑的环形缓冲区
self.ring_buffer = collections.deque(maxlen=30) # 600ms
self.triggered = False
def process_frame(self, pcm_bytes):
"""
处理一帧音频,返回是否需要发送
"""
is_speech = self.vad.is_speech(pcm_bytes, self.sample_rate)
if not self.triggered:
# 未触发状态:积累语音帧
self.ring_buffer.append((pcm_bytes, is_speech))
num_voiced = sum(1 for _, speech in self.ring_buffer if speech)
# 如果 90% 的帧都是语音,触发
if num_voiced > 0.9 * self.ring_buffer.maxlen:
self.triggered = True
# 把缓冲区的数据一起发出去
return b''.join([f for f, _ in self.ring_buffer])
return None
else:
# 已触发状态
if is_speech:
self.ring_buffer.append((pcm_bytes, True))
return pcm_bytes
else:
self.ring_buffer.append((pcm_bytes, False))
num_unvoiced = sum(1 for _, speech in self.ring_buffer if not speech)
# 如果 90% 都是静音,结束触发
if num_unvoiced > 0.9 * self.ring_buffer.maxlen:
self.triggered = False
self.ring_buffer.clear()
return pcm_bytes使用的时候大概是这样:
vad = VADProcessor(aggressiveness=2)
async def handle_client_audio(websocket, gemini_ws):
async for message in websocket:
data = json.loads(message)
if 'audio' in data:
pcm_bytes = base64.b64decode(data['audio'])
# VAD 检测
result = vad.process_frame(pcm_bytes)
if result:
# 有人说话,转发给 Gemini
await send_audio(gemini_ws, base64.b64encode(result).decode())aggressiveness 这个参数挺微妙的。设得太低,稍微有点背景噪音就认为是语音;设得太高,轻声说话可能被漏掉。我的经验是先从 2 开始,根据实际场景微调。
如果你的部署环境装不了 webrtcvad,也可以用简单的能量阈值检测作为备选方案:
// 前端备选方案:基于 RMS 能量的简单检测
function detectVoiceActivity(audioData, threshold = 0.015) {
const sum = audioData.reduce((acc, val) => acc + val * val, 0);
const rms = Math.sqrt(sum / audioData.length);
return rms > threshold;
}自然插话(Barge-in)功能实现
不知道你有没有这种感觉:跟某些语音助手聊天的时候,一旦它开始长篇大论,你就只能干等着,想打断都不行,特别憋屈。
Barge-in(插话)功能就是解决这个问题的。当 AI 在说话的时候,用户可以直接开口打断,AI 会立即停止当前输出,听用户说什么。
好消息是,Gemini Live API 原生就支持这个功能,而且做得还挺智能。你只需要在配置里开启自动活动检测:
CONFIG = {
"setup": {
"model": "models/gemini-2.0-flash-native-audio-preview",
"generation_config": {
"response_modalities": ["AUDIO"],
},
"realtime_input_config": {
"automatic_activity_detection": {
"disabled": False,
"start_of_speech_sensitivity": "START_SENSITIVITY_HIGH",
"end_of_speech_sensitivity": "END_SENSITIVITY_LOW"
}
}
}
}sensitivity 的配置有点讲究:
start_of_speech_sensitivity设成HIGH意味着 AI 对用户开始说话更敏感,更容易触发打断end_of_speech_sensitivity设成LOW意味着 AI 会等多确认一会儿用户真的说完了才响应,避免误判
客户端这边要做的就是监听 interrupted 事件,然后立即停止播放:
class GeminiClient {
constructor() {
this.audioQueue = [];
this.isPlaying = false;
this.currentSource = null;
}
async handleMessage(event) {
const message = JSON.parse(event.data);
// 处理中断信号
if (message.server_content?.interrupted) {
console.log('⚡ 用户打断了,停止播放');
this.stopPlayback();
return;
}
// 处理 AI 返回的音频
if (message.server_content?.model_turn) {
const parts = message.server_content.model_turn.parts;
for (const part of parts) {
if (part.inline_data?.mime_type.startsWith('audio/')) {
const audioData = base64ToArrayBuffer(part.inline_data.data);
this.queueAudio(audioData);
}
}
}
}
stopPlayback() {
// 清空播放队列
this.audioQueue = [];
this.isPlaying = false;
// 停止当前正在播放的音频
if (this.currentSource) {
try {
this.currentSource.stop();
} catch (e) {
// 可能已经停止了
}
this.currentSource = null;
}
}
async queueAudio(audioData) {
this.audioQueue.push(audioData);
if (!this.isPlaying) {
this.playNext();
}
}
async playNext() {
if (this.audioQueue.length === 0) {
this.isPlaying = false;
return;
}
this.isPlaying = true;
const audioData = this.audioQueue.shift();
// 解码并播放
const audioBuffer = await this.audioContext.decodeAudioData(audioData.slice());
this.currentSource = this.audioContext.createBufferSource();
this.currentSource.buffer = audioBuffer;
this.currentSource.connect(this.audioContext.destination);
this.currentSource.onended = () => {
this.playNext();
};
this.currentSource.start();
}
}这里要注意一个细节:stop() 方法可能会抛出异常,如果音频已经自然播放完了的话。所以我加了个 try-catch,免得控制台一片红。
性能优化与延迟控制
最后来聊聊怎么把这个系统的延迟压到最低。
首先我们要知道延迟从哪来:
- 网络传输:数据包从浏览器到服务器再到 Gemini 的往返时间
- 音频编解码:PCM 压缩/解压的时间(不过 PCM 本身是无损的,这部分开销很小)
- 缓冲区累积:为了平滑播放而设置的缓冲深度
针对这几点,我的优化经验是:
减少缓冲深度
播放缓冲区不要设太大,够用就行。我一般用 100-200ms:
// 设置较小的缓冲区
const audioContext = new AudioContext({
sampleRate: 16000,
latencyHint: 'interactive' // 低延迟模式
});自适应比特率(其实这里主要是自适应缓冲)
如果检测到网络抖动比较大,可以适当增加一点缓冲;网络稳定的时候就减下来。
本地回声消除
如果用户开着扬声器而不是戴耳机,AI 的声音会被麦克风收进去,形成循环。好在 getUserMedia 自带了回声消除:
navigator.mediaDevices.getUserMedia({
audio: {
echoCancellation: true,
noiseSuppression: true,
autoGainControl: true
}
})监控指标
怎么知道自己优化得有没有效果?可以用 Performance API 打点:
// 记录延迟指标
class LatencyMonitor {
constructor() {
this.metrics = [];
}
recordSendTime() {
this.lastSendTime = performance.now();
}
recordReceiveTime() {
const latency = performance.now() - this.lastSendTime;
this.metrics.push(latency);
// 保持最近 100 条记录
if (this.metrics.length > 100) {
this.metrics.shift();
}
// 计算平均延迟
const avg = this.metrics.reduce((a, b) => a + b, 0) / this.metrics.length;
console.log(`📊 平均延迟: ${avg.toFixed(2)}ms`);
}
}我在测试环境里测下来的数据大概是:
- 端到端延迟:300-500ms(取决于网络状况)
- 首包响应时间:200-400ms
- 连续对话延迟:150-300ms
如果你的延迟明显高于这个数值,可以按这个清单排查:
- WebSocket 连接是不是走了 HTTPS/WSS?HTTP 会有额外开销
- 服务器部署在哪?离 Google 的数据中心越近越好
- VAD 检测有没有引入过多延迟?试试减小帧长
- 前端播放缓冲区是不是设太大了?
还有一个坑是关于音频上下文的:Chrome 要求用户交互后才能播放声音,所以记得在页面里加个”开始对话”的按钮,别一上来就自动播放。
小结
到这里,我们已经走完了一个完整的 Gemini Live API 应用开发流程。从最初的概念介绍,到架构设计、WebSocket 连接、音频采集、VAD 检测、插话功能,再到最后的性能优化,每一步我都尽量把自己踩过的坑分享了出来。
说实话,实时语音交互这个领域还在快速发展中,Gemini Live API 本身也在持续更新。但我相信这套基础架构是经得起考验的——至少我自己的项目已经跑了好几个月,稳定性还不错。
如果你在实际开发中遇到了什么问题,欢迎随时交流。毕竟技术这东西,一个人摸索总是慢一些,大家一起讨论才能进步更快。
常见问题
为什么必须使用前后端分离架构?
为什么选择16kHz采样率?
VAD的aggressiveness参数怎么调?
Barge-in功能需要额外开发吗?
10 分钟阅读 · 发布于: 2026年2月27日 · 修改于: 2026年3月18日
相关文章
OpenClaw 2026.3 实战进阶:新版本核心功能与最佳实践

OpenClaw 2026.3 实战进阶:新版本核心功能与最佳实践
OpenClaw 实战完全手册:从入门到精通

OpenClaw 实战完全手册:从入门到精通
不做单一模型的囚徒:在 Antigravity 中灵活切换 Gemini 3、Claude 4.5 与 GPT-OSS

评论
使用 GitHub 账号登录后即可评论