
RAG + Agent:次世代 AI アプリケーションのアーキテクチャ
ある企業が 3 か月かけて構築した RAG システムは、リリース初週で上司に名指しで批判されました——「これ、なんで簡単な出張費精算の質問にもまともに答えられないんだ?」
従来型 RAG は、辞書を引くことしかできない学生のようなものです。聞かれたことをそのまま調べるだけで、質問の背後にある意図をまったく考えません。ユーザーが「先月の出張費精算が却下されたが、理由は何か」と尋ねると、従来型 RAG は出張ポリシーの文書を大量に検索してくるかもしれませんが、まずユーザーの具体的な精算記録を調べるべきだということがわかりません。
これこそが Agentic RAG が解決しようとしている問題です。
この記事では、RAG + Agent の統合アーキテクチャについて話します。これは企業の AI アプリケーションを作り変えつつある技術ソリューションです。アーキテクチャの進化からフレームワーク選定、さらに具体的な導入ロードマップまで触れていきます。AI カスタマーサポートの実践事例も紹介するので、何かのヒントになれば幸いです。
従来型 RAG から Agentic RAG へ:アーキテクチャの進化
従来型 RAG の仕組みは実はとてもシンプルです。ユーザーの質問 → ベクトル検索 → 関連文書を取得 → LLM に渡して回答を生成。3 ステップで完了です。
このアーキテクチャの利点は明確です。速く、安く、実装が容易。ただし、それに伴う問題もあります。
検索が不正確。ユーザーが曖昧な質問をすると、ベクトル類似度検索は「似ているように見えるが実際は無関係」な文書を大量に見つけてくるかもしれません。たとえば「データベース接続をどう設定するか」と聞くと、検索結果に MySQL と PostgreSQL の文書が混ざってしまい、ユーザーが自分で見分ける必要があります。
推論ができない。従来型 RAG は「検索-生成」という動作しかできず、複数ステップが必要な問題に直面するとお手上げです。「案 A と案 B のメリット・デメリットを比較して」と聞くと、片方の案の文書しか検索できず、もっともらしく的外れなことを語り出すかもしれません。
"McKinsey の調査によると、GenAI ユーザーの 47% がネガティブな影響を経験しており、すべての出力をレビューするユーザーはわずか 27% にとどまる"
Agentic RAG がもたらす変化
Agentic RAG の核心的な考え方は、AI に検索-生成を機械的に実行させるのではなく、どう問題を解決するかを能動的に「考えさせる」ことです。
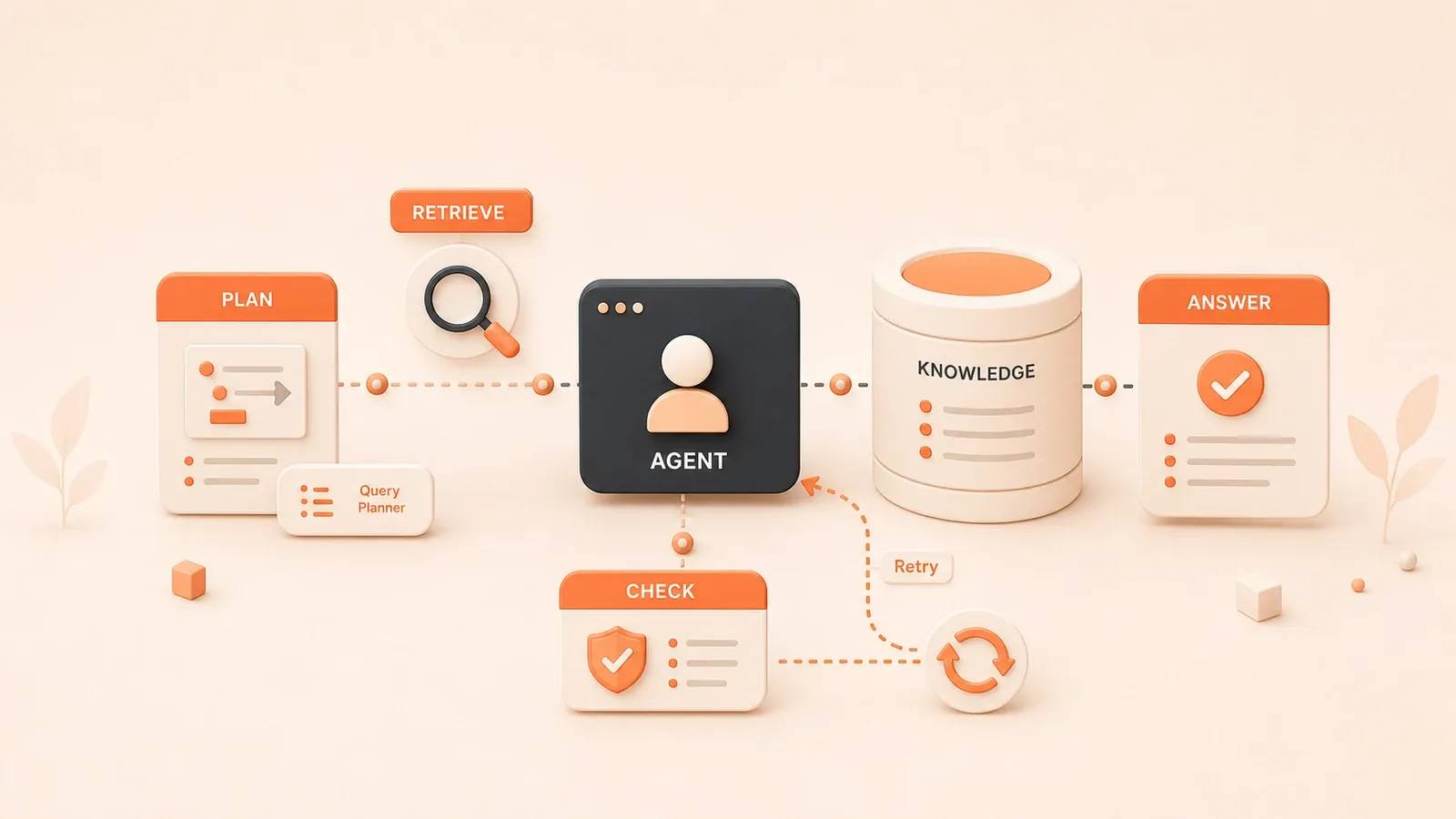
その中核ループは次のとおりです。
Plan → Retrieve → Act → Reflect → Answer一つずつ説明します。
Plan(計画):まずユーザーの問題を分析し、サブタスクに分解します。「先月の出張費精算が却下された」という問題は、ユーザーの精算記録を調べる・出張ポリシーを調べる・却下理由を比較分析する、に分解できます。
Retrieve(検索):計画に基づき、どこから何を検索するかを決めます。ナレッジベース、データベース、さらには外部 API の呼び出しまで同時に必要になることもあります。
Act(行動):検索を実行し、ツールを呼び出し、情報を取得します。この段階で新たな問題が見つかり、再度の計画が必要になることもあります。
Reflect(振り返り):検索結果が十分か、回答が妥当かを評価します。不十分なら、Plan 段階に戻ってやり直すこともあります。
Answer(回答):最終的に回答を生成し、引用元を添えます。
要するに、従来型 RAG は辞書を引くようなもの。Agentic RAG はリサーチアシスタントがいるようなもの——問題を分析し、資料を調べ、情報を照合してから、信頼できる答えを返してくれます。
この数字の背景には、AI の能力に対する企業の期待が「使える」から「使いやすい」へと高まっていることがあります。Agentic RAG は、まさにこのアップグレードの鍵となる一歩です。
10 種類の RAG アーキテクチャパターンを詳解
ここは内容が多いので、要点を絞って説明します。完全なアーキテクチャ比較表は後ろに置いておくので、まずは全体像をつかんでください。
Naive RAG:入門レベルの選択肢
最もシンプルなアーキテクチャです。ユーザーの質問 → ベクトル検索 → 回答生成。アイデアを素早く検証するには適していますが、本番環境では基本的に力不足です。
典型的な問題は、検索精度の低さ、コンテキストウィンドウの浪費、深刻なハルシネーション。個人的には、POC や社内ツールを作るときだけ使うことをおすすめします。
Hybrid RAG:企業の本番運用での標準構成
このパターンは、今や企業の本番運用での基準になっています。中核となる考え方は、2 種類の検索方式を組み合わせることです。語彙検索(キーワードマッチ)と意味検索(ベクトル類似度)です。
なぜでしょうか。2 種類の検索方式にはそれぞれ強みがあるからです。語彙検索は正確なマッチが得意で、意味検索は意図の理解が得意。組み合わせれば、当然ながら効果が高まります。
実装としては、BM25 で語彙検索を行い、ベクトルデータベース(Pinecone、Weaviate、Milvus など)で意味検索を行い、Reciprocal Rank Fusion(RRF)で結果を統合できます。
Graph RAG:マルチホップ推論の切り札
業務シーンで「なぜ」「どう関連しているか」といった問いに答える必要があるなら、Graph RAG は検討に値します。
文書からエンティティを抽出してナレッジグラフを構築し、マルチホップ推論をサポートします。たとえば「どの製品がこのサプライヤーの部品を使っているか」と聞けば、Graph RAG はグラフの関係チェーンをたどって答えを見つけられます。
代償として、コストは基本的な RAG より 3〜5 倍高くなります——ナレッジグラフの構築と保守はどちらも安くありません。
Agentic RAG:能動的に思考するタイプ
中核ループは前述したとおりです。ここで一点補足すると、Agentic RAG の柔軟性は諸刃の剣です。
利点は複雑な問題を処理できること。欠点はレイテンシが高く、コストが制御しにくいこと。単純な質問でも複数回の検索やツール呼び出しを引き起こし、API 呼び出し費用がどんどん膨らみます。そのため実際の運用では、通常ルーティング戦略を併用します——単純な質問は従来型 RAG に流し、複雑な質問だけ Agentic フローに入れます。
Self-RAG:自己修正タイプ
このパターンの核心は、モデルに自分の出力を評価させることです。検索した文書は十分に関連しているか。生成した回答にハルシネーションはないか。
評価を通過しなければ、モデルは能動的に再検索したり回答を修正したりします。聞こえはよいですが、推論コストが増え、評価自体が誤る可能性もあります。
Agentic Graph RAG:天井クラス
現時点で最も先進的なパターンです。Agent のオーケストレーション能力をナレッジグラフ検索に組み込み、マルチホップ推論能力と能動的な計画能力の両方を備えます。
もちろん、コストも天井クラス——中核業務のシーンでのみ使うことをおすすめします。
アーキテクチャパターン比較表
| アーキテクチャパターン | 複雑度 | 適用シーン | 相対コスト | レイテンシ |
|---|---|---|---|---|
| Naive RAG | 低 | 高速検証、社内ツール | 1x | <1s |
| Hybrid RAG | 中 | 企業の本番運用での標準構成 | 1.5x | 1-2s |
| Graph RAG | 高 | マルチホップ推論、知識集約型 | 3-5x | 2-4s |
| Agentic RAG | 高 | 複雑な意思決定、複数ステップのタスク | 3-8x | 3-10s |
| Self-RAG | 中〜高 | 高精度が求められるシーン | 2-3x | 2-4s |
| Agentic Graph RAG | 極めて高い | 中核業務、複雑な推論 | 5-10x | 5-15s |
Hybrid RAG から始め、実際のニーズに応じて段階的にアップグレードすることをおすすめします。最初から最先端のアーキテクチャを追い求めると、失敗しやすいです。
フレームワーク選定:LangChain vs LlamaIndex vs CrewAI vs AutoGen
ここは私自身が痛い目に遭いました。以前あるプロジェクトで、最初にあるフレームワークを選んだのですが、途中でエコシステムが未成熟だと気づき、やむなく作り直すことになりました。時間の無駄になるだけでなく、チームの士気にも影響しました。
ですからフレームワーク選定は本当に重要です。主要なフレームワークの特徴と利用シーンをまとめてみたので、遠回りを減らす助けになれば幸いです。
LangChain / LangGraph:エコシステムが最も充実
どれを選べばよいかわからないなら、LangChain を選んでおけば基本的に間違いありません。現時点でエコシステムが最も整っているフレームワークで、ドキュメントが充実し、コミュニティも活発。GitHub stars は 25K を超えています(LangGraph)。
LangGraph は LangChain チームが提供するグラフ状態機械フレームワークで、ステートフルな Agent ワークフローの構築に特化しています。その中核的な強みは本番級の永続化をサポートすること——Agent の状態をデータベースに保存でき、再開やタイムトラベルデバッグに対応します。
適したシーン:本番級のワークフロー、状態の永続化が必要なケース、複雑な Agent オーケストレーション。
# LangGraph 簡易例:クエリ計画エージェント
from langgraph.graph import StateGraph
def plan_query(state):
"""ユーザーの問題を分析し、検索ステップを計画する"""
query = state["query"]
# 問題を分解し、サブクエリを生成する
sub_queries = decompose(query)
return {"sub_queries": sub_queries}
def retrieve(state):
"""検索を実行する"""
results = []
for q in state["sub_queries"]:
docs = retriever.invoke(q)
results.extend(docs)
return {"context": results}
# ワークフローを構築する
workflow = StateGraph(AgentState)
workflow.add_node("plan", plan_query)
workflow.add_node("retrieve", retrieve)
workflow.add_edge("plan", "retrieve")LlamaIndex:データ集約型の第一候補
業務シーンで大量の非構造化データ(文書、データベース、API)を扱うなら、LlamaIndex がより優れた選択肢です。
クエリエンジンの設計が非常によく、ベクトル検索、キーワード検索、ハイブリッド検索、ナレッジグラフ検索など複数の検索戦略をサポートします。さらに、さまざまなデータソース向けのコネクタも充実しています。
適したシーン:データ集約型の RAG アプリケーション、複数のデータソースと連携する必要があるケース、検索品質を重視するケース。
CrewAI:高速プロトタイプの切り札
CrewAI の売りは「役割駆動のマルチエージェントチーム」です。複数の Agent の役割を定義し、協力してタスクを完了させることができます。
たとえばコンテンツ制作チームを設計します。リサーチャーが資料収集を担当し、ライターが執筆を担当し、エディターが校正を担当。各役割には独自の目標とツールがあります。
適したシーン:高速プロトタイプ検証、業務フローの自動化、役割分担が明確なタスク。
現在 CrewAI の開発者コミュニティは 10 万人を超え、GitHub stars は 20K を超えており、エコシステムは急速に発展しています。
AutoGen:マイクロソフトが後押しするマルチエージェントフレームワーク
AutoGen はマイクロソフトリサーチがオープンソース化したマルチエージェントフレームワークで、対話型の協調を主軸にしています。複数の Agent が対話を通じてタスクを完了させ、複数回のやり取りが必要なシーンに適しています。
特徴は人間と機械の協調をサポートすること——人間がいつでも対話に介入し、Agent の方向を修正できます。
適したシーン:研究プロジェクト、人間と機械の協調が必要な複雑なタスク、対話型のやり取り。
GitHub stars は 50K を超え、現時点で stars 数が最も多い Agent フレームワークです。
選定の意思決定ツリー
簡単な意思決定ロジックを描いてみました。
あなたのプロジェクトはどんな種類ですか?
├── 本番級の永続化ワークフロー → LangGraph
├── データ集約型 RAG → LlamaIndex
├── 高速プロトタイプ/業務フロー → CrewAI
├── 研究/対話型マルチエージェント → AutoGen
└── 不確定/最大限の柔軟性が必要 → LangChain + LangGraphとはいえ、フレームワーク選定に正解はありません。チームの技術スタックとプロジェクトのニーズに応じて選び、同時にフレームワークの更新頻度とコミュニティの活発さに注目することをおすすめします——ここは後々の保守コストに直結します。
エンタープライズ導入ロードマップ
ここでは複数の企業の実践経験に基づき、90 日の導入テンプレートをまとめました。もちろん、各社のペースは異なるので、実情に応じて調整してかまいません。
第 1 フェーズ:Day 0〜15、課題と KPI を定義する
多くの人がいきなり技術選定に走りますが、これは間違いです。まず明確にすべきは、私たちはどんな課題を解決したいのか、ということです。
いくつかの重要な問いに答える必要があります。
- ユーザーは誰か?社内の従業員か、それとも社外の顧客か。
- 中核となるシーンは何か?Q&A、検索、それとも複雑な推論か。
- 成功指標をどう定めるか?精度、応答時間、ユーザー満足度か。
この段階では、簡単なユーザー調査を行い、50〜100 件の実際の質問を集めることをおすすめします。これらの質問は後でテストセットと評価基準になります。
第 2 フェーズ:Day 16〜45、データ準備と検索層
データ準備は体力勝負ですが、システムの上限を決めます。
データクレンジング:重複、古い、機密の内容を取り除きます。このステップは見落とされがちですが、汚いデータは検索品質に深刻な影響を与えます。
チャンク分割戦略:文書の種類に応じて適切なチャンクサイズを選びます。技術文書なら 500〜1000 文字で 1 チャンク、法律条文なら条項ごとに区切る必要があるかもしれません。
Embedding の選定:OpenAI の text-embedding-3 シリーズ、Cohere、BGE はどれも優秀です。まず小さなデータセットで比較テストすることをおすすめします。
検索層の構築:Hybrid RAG から始め、BM25 とベクトル検索を組み合わせます。
第 3 フェーズ:Day 46〜75、Agent オーケストレーションとツール統合
この段階から Agent の能力を導入します。
ルーティング戦略:すべての質問に Agent が必要なわけではありません。単純な FAQ の質問は直接従来型 RAG に流し、複雑な質問だけ Agent フローに入れます。こうすればコストとレイテンシを抑えられます。
ツール統合:MCP プロトコルで社内システムに接続します。データベースクエリ、API 呼び出し、文書検索などが含まれるかもしれません。
オーケストレーション設計:LangGraph や類似のツールでワークフローを設計します。シンプルな ReAct パターンから始め、徐々に複雑さを増やすことをおすすめします。
第 4 フェーズ:Day 76〜90、評価、テスト、堅牢化
評価については、RAGAS フレームワークの利用をおすすめします。主に 3 つの指標に注目します。
- Faithfulness(忠実度):生成した回答が検索した文書に忠実かどうか、目標 >= 0.8
- Answer Relevance(回答の関連性):回答がユーザーの問いに答えているか
- Context Relevance(コンテキストの関連性):検索した文書が十分に関連しているか
ほかにもいくつかの技術指標があります。
- Recall@K >= 0.85:検索上位 K 件のリコール率
- P95 latency <= 2.5s:95% のリクエストの応答時間
- コスト管理:1 リクエストあたりの API 呼び出し回数と Token 消費
よくある落とし穴
最後に、踏みやすい落とし穴をいくつか挙げておきます。
- アクセス制御の回避:Agent がツール呼び出しを通じて権限制御を回避するおそれがあるので、セキュリティテストは十分に行うこと
- コンテキストの失効:長い対話では初期の情報が失われることがあるので、コンテキスト管理戦略を設計する必要がある
- コストの暴走:Agent が複数回の検索を引き起こすことがあり、API 呼び出し費用が急速に積み上がる
実践事例:AI カスタマーサポートのアーキテクチャ設計
この事例は以前ある企業向けに手がけたもので、なかなかの効果でした。
シーン:企業のカスタマーサポートは、製品、注文、アフターサービス、ポリシーなど多方面にわたるユーザーの質問に答える必要があります。これらの情報はナレッジベース、CRM システム、注文システム、ERP システムに分散しています。
課題:従来型 RAG はナレッジベースしか検索できず、ユーザーの注文状況や履歴などのパーソナライズされた情報を照会できません。
アーキテクチャ設計
3 層の Agent アーキテクチャを設計しました。
第 1 層:Routing Agent(ルーティングエージェント)
ユーザーの問題を分析し、次にどの分岐に進むかを決めます。たとえば次のとおりです。
- 「製品の使い方」 → ナレッジベース検索へ
- 「私の注文はどこまで来ている」 → 注文システム照会へ
- 「返金ポリシーは何か」 → ポリシー文書検索へ
第 2 層:Query Planning Agent(クエリ計画エージェント)
複雑な問題については、複数のサブクエリに分解します。たとえばユーザーが「先月買ったスマホは返品できるか」と聞いた場合、次が必要です。
- ユーザーの注文記録を照会する
- 返品ポリシーを照会する
- 注文日とポリシーの有効期限を比較する
第 3 層:ReAct Agent(推論行動エージェント)
具体的な検索とツール呼び出しを実行し、複数回の反復をサポートします。
ツール統合
MCP プロトコルで社内システムに接続します。
tools:
- name: knowledge_search
type: vector_retrieval
source: product_docs
- name: order_query
type: api_call
endpoint: /api/orders/{user_id}
- name: policy_search
type: hybrid_retrieval
sources: [policy_docs, faq]効果の比較
リリース後、従来型 RAG と Agentic RAG の効果を比較しました。
| 指標 | 従来型 RAG | Agentic RAG |
|---|---|---|
| 問題解決率 | 45% | 78% |
| 平均応答時間 | 1.2s | 3.5s |
| ユーザー満足度 | 3.2/5 | 4.1/5 |
| 人手介入率 | 55% | 22% |
問題解決率は 33 ポイント向上し、人手介入率は半分以下に低下しました。代償として応答時間は増えました——これは Agent アーキテクチャの必然的な代償であり、体験と効率の間でトレードオフを取る必要があります。
結論
RAG + Agent は、企業 AI アプリケーションの標準アーキテクチャになりつつあります。受動的な検索から能動的な推論へ——このアーキテクチャは AI が本当に複雑な問題を処理できるようにします。
いくつかの提案:
-
シンプルに始める。いきなり Agentic Graph RAG を追い求めず、Hybrid RAG から始め、価値を検証してからアップグレードしましょう。
-
コスト管理に注目する。Agent の柔軟性には代償があり、API 呼び出し費用は簡単に暴走します。ルーティング戦略とキャッシュ機構は欠かせません。
-
評価体系を重視する。定量指標がなければ、システムが良いのか悪いのか永遠にわかりません。RAGAS フレームワーク + 自前のテストセット、これが基本です。
-
オープンプロトコルに注目する。MCP はツール接続の標準になりつつあり、A2A プロトコルもフレームワーク間の協調問題を解決しようとしています。これらのプロトコルは Agent エコシステムの発展に深く影響するでしょう。
以上が概要です。RAG システムを構築中なら、この記事が何かの参考になれば幸いです。質問があればコメントで議論しましょう。
FAQ
Agentic RAG と従来型 RAG の本質的な違いは何ですか?
企業はどの RAG アーキテクチャを選ぶべきですか?
LangChain、LlamaIndex、CrewAI はどう選べばよいですか?
• 本番級の永続化ワークフロー → LangGraph
• データ集約型 RAG → LlamaIndex
• 高速プロトタイプ/業務フロー → CrewAI
• 研究/対話型マルチエージェント → AutoGen
Agentic RAG のコストとレイテンシはどう抑えますか?
RAG + Agent プロジェクトの導入にはどのくらい時間がかかりますか?
RAG システムの効果はどう評価しますか?
• Faithfulness(忠実度)>= 0.8
• Answer Relevance(回答の関連性)
• Context Relevance(コンテキストの関連性)
技術指標:Recall@K >= 0.85、P95 レイテンシ <= 2.5s
9分で読めます · 公開日: 2026年3月22日 · 更新日: 2026年7月14日
RAG エンジニアリング: アーキテクチャ、vector DB、query routing、knowledge ops
このページはシリーズの最初の記事です。次の記事へ進むか、シリーズ全体ページで全体像を確認できます。


コメント
GitHubアカウントでログインしてコメントできます