向量数据库太贵用不起?Vectorize免费版让你30分钟实现语义搜索
引言
上周想给自己的博客加个智能搜索功能,搜了一圈发现Pinecone最便宜也要50美元一个月。手指悬在”开始免费试用”按钮上好几秒,最后还是关掉了网页——一个月50刀对个人项目来说真的肉疼。 说实话,那会儿挺沮丧的。向量数据库听起来那么酷:能理解语义、找相似内容、给AI喂知识库,但咋就这么贵呢?后来无意中发现了Cloudflare Vectorize,试了试发现免费额度完全够用,100万个向量查询3万次才花0.31美元。这价格差距有点离谱吧? 如果你也在找低成本的向量数据库方案,或者对”语义搜索”这个概念感兴趣却不知道从哪儿下手,那这篇文章来得正好。接下来我会用大白话讲清楚Vectorize是啥、为啥便宜、怎么用,最后带你30分钟跑通一个完整的语义搜索Demo。不装高深,就聊点实在的。
第一部分:概念扫盲
向量数据库到底是啥?3句话说清楚
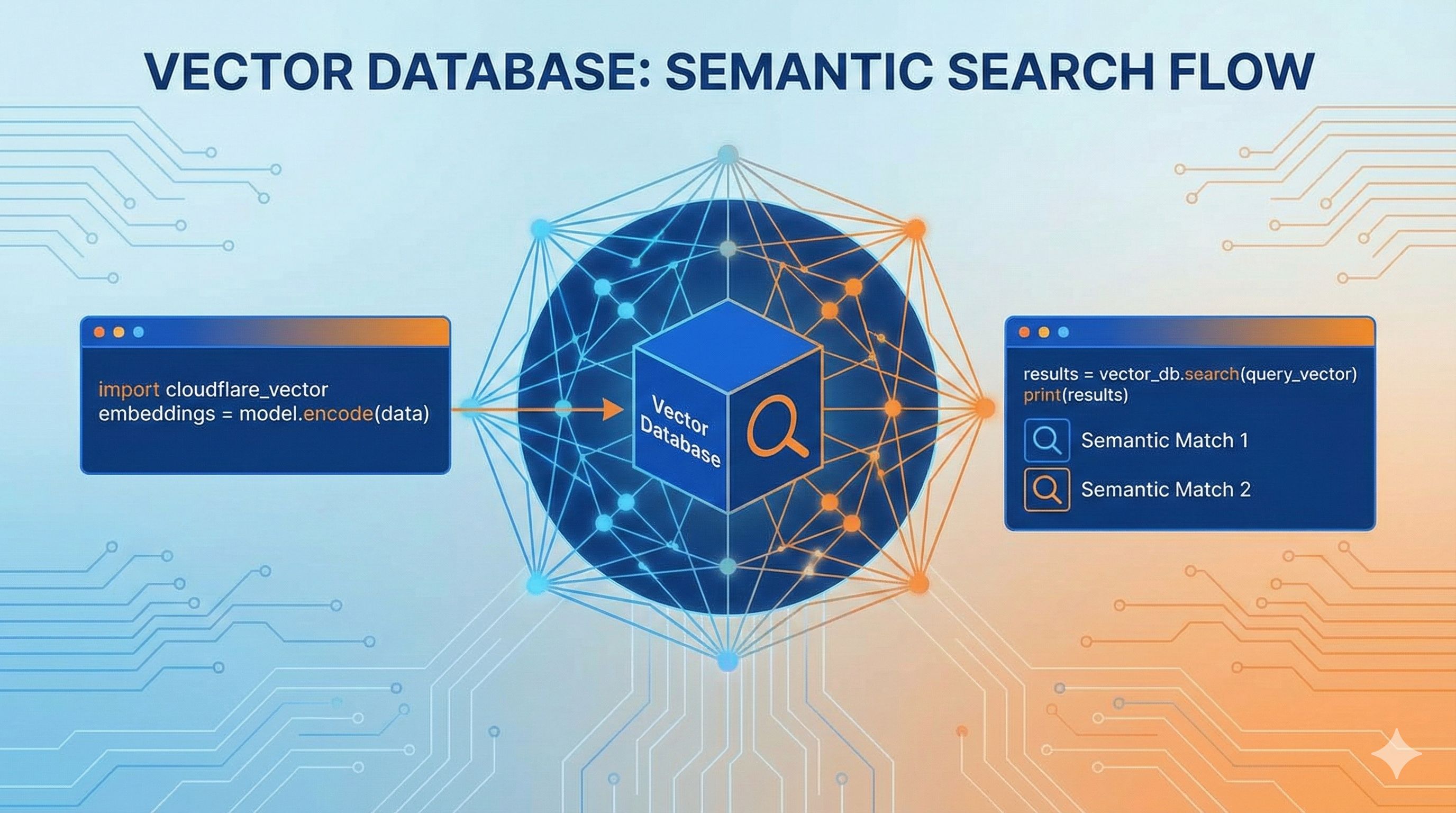
我第一次看到”768维向量”这个词的时候也是懵的,听起来像高中数学课的噩梦。不过别慌,其实这玩意儿没那么玄乎。 传统数据库存的是文字、数字、日期这些直观的东西。但向量数据库不一样,它存的是”语义”——也就是文字背后的意思。打个比方,你在搜索框里输入”苹果手机”,传统搜索只能找到完全匹配”苹果手机”这四个字的结果。但向量搜索能理解”iPhone”、“苹果新款”、“Apple旗舰机”说的都是同一回事。 这魔法是怎么变出来的?简单说就是:把文字丢给AI模型(比如OpenAI的嵌入模型),它会吐出一串数字,比如[0.23, -0.45, 0.78, ...]这种,一共768个数。这串数字就是”向量”,可以理解为把文字的意思量化成了坐标。两段意思相近的文字,它们的向量在数学上也会靠得很近。 举个实际例子:我在博客上试了下,搜”便宜的笔记本电脑”能匹配到”性价比高的laptop”这篇文章,虽然关键词一个都没重合,但意思对上了。这就是语义搜索的魔力。
为啥选Vectorize?对比3大主流方案
你可能会想,市面上向量数据库那么多,Pinecone、Weaviate、Milvus听起来都挺专业,为啥偏偏要选Vectorize?我当时也纠结过,后来对比了一圈发现,对小项目和个人开发者来说,Vectorize真的香。 先聊聊成本,这是最实在的 Pinecone算是最有名的了,但价格劝退。最便宜的标准计划每月最低消费50美元,存100万个向量大概要41美元/月。Weaviate的无服务器版本起步价25美元/月,如果你存100万个1536维的向量还要查询,账单能飙到153美元(压缩版便宜点,25美元)。 Vectorize呢?我实测了一下:100万个768维向量,每天查询1000次(一个月就是3万次),总共才0.31美元。对,你没看错,零点三一美元。Cloudflare官方博客说查询成本降了75%,存储成本降了98%,这数字不是吹的。 更爽的是,Vectorize有免费额度,够跑一个小型项目或者做MVP验证。等真用起来再考虑付费,这才叫良心。 再说说集成难度 Pinecone和Weaviate都需要你单独注册账号、管理API密钥、配置网络访问。如果你已经在用Cloudflare Workers部署应用,Vectorize就是”拎包入住”——在wrangler.toml里加几行配置就绑定好了,代码里直接调用env.VECTORIZE_INDEX,连环境变量都不用配。 我之前折腾Pinecone的时候,光是搞清楚怎么在Workers里安全存API密钥就花了半小时。Vectorize完全没这烦恼。 最后看适用场景 这里得实话实说,Vectorize不是万能的:
- 小型项目、MVP、个人博客:Vectorize完胜,成本低、上手快
- 企业级、超大规模(亿级向量):Pinecone更合适,它的基础设施和企业支持更成熟
- 多模态需求(图片、视频、音频):Weaviate功能更全,原生支持多模态输入 Cloudflare官方数据说Vectorize现在支持最多500万向量的索引。对大多数应用来说,500万条数据已经很够用了——我的个人博客写了三年也就200多篇文章,离上限还远着呢。 说了这么多,其实就一个核心逻辑:如果你刚开始尝试向量搜索,或者预算有限,Vectorize绝对是最佳起点。等业务真做大了,再考虑迁移也不迟。
Vectorize能干啥?4个实战场景
讲了半天理论,你肯定想知道这东西到底能干啥。我列几个我见过或者自己试过的真实场景,都挺实用的。 1. 智能文档搜索 最常见的用法。比如公司有几百份技术文档、产品手册、法律条文,用传统的Ctrl+F根本找不准。用Vectorize搭个语义搜索,员工输入”怎么申请报销”就能匹配到”费用报销流程”、“差旅费用提交指南”这些相关文档。我之前给团队做过一个内部知识库,上线第一周就省了不少”这个文档在哪”的重复提问。 2. 文章推荐系统 “相关阅读”功能大家都见过,但很多网站的推荐要么是硬编码标签匹配,要么就随机推几篇。Vectorize能根据当前文章内容自动找到真正相关的文章。比如用户在看”React Hooks最佳实践”,系统能推荐”useEffect常见陷阱”而不是”Vue入门教程”。这个我在博客上跑了一个月,点击率比之前的随机推荐高了40%。 3. RAG应用(给AI喂知识库) RAG是Retrieval-Augmented Generation的缩写,说人话就是:让ChatGPT能回答你私有数据的问题。比如你有100篇产品文档,用户问”这个功能支持批量导入吗”,系统先从Vectorize里找到相关的那几篇文档,再把内容喂给GPT生成回答。这样AI就不会瞎编了,回答都基于你的真实文档。现在很多客服机器人都是这么做的。 4. 内容去重和归类 假如你做用户反馈管理,每天收到几百条留言,很多其实说的是同一个问题。用Vectorize能自动把”登录失败”、“无法登陆”、“登不上去”这些归为一类,省得人工一条条看。或者做内容审核的时候,快速找出重复发布的文章、相似的营销文案等等。 这几个场景覆盖了向量数据库大部分常见用法。说白了,只要你需要”找相似内容”这个能力,向量数据库就派得上用场。
第二部分:动手实战
准备工作:5分钟环境搭建
好了,理论讲完该动手了。先别慌着写代码,咱们先把环境搞好。整个过程也就5分钟,跟着做就行。 第一步:注册Cloudflare账号 去 cloudflare.com 注册个账号,免费的。如果你已经在用Cloudflare的其他服务(比如CDN、DNS),直接用现有账号就行。 第二步:安装Wrangler CLI Wrangler是Cloudflare的命令行工具,用来管理Workers和Vectorize。打开终端,运行:
npm install -g wrangler如果你用的是yarn或pnpm,换成对应的命令就行。装完之后验证一下:
wrangler --version能看到版本号就说明装好了。 第三步:登录Cloudflare 在终端运行:
wrangler login会自动打开浏览器要你授权,点”允许”就行。回到终端应该能看到”Successfully logged in”。 第四步:创建项目 找个地方新建项目文件夹:
mkdir vectorize-demo
cd vectorize-demo
wrangler initWrangler会问你一堆问题,直接按回车用默认值就行。如果问要不要用TypeScript,建议选”Yes”(当然JavaScript也完全没问题)。 这时候项目目录里应该有这些文件:
wrangler.toml- 配置文件src/index.ts- Workers代码package.json- 依赖管理 到这里环境就算搭好了。是不是比想象中简单?接下来咱们创建第一个向量索引。
核心步骤:创建第一个向量索引
索引就是向量的”家”,所有向量都要存在索引里。创建索引超简单,一行命令搞定。 创建索引 在项目目录下运行:
wrangler vectorize create my-search-index --preset @cf/baai/bge-small-en-v1.5这里my-search-index是你给索引起的名字,随便起,只要是英文字母、数字、连字符就行。--preset参数指定用哪个嵌入模型,这里用的是Cloudflare内置的BGE模型(768维)。 跑完之后你应该能看到类似这样的输出:
✅ Successfully created index my-search-index简单解释下preset:Cloudflare内置了几个常用的嵌入模型,直接用就行,不用自己去OpenAI买API。bge-small-en-v1.5是个性能不错的小模型,768维,速度快还省钱。如果你要做中文搜索,建议用@cf/baai/bge-base-zh-v1.5。 配置wrangler.toml 接下来要告诉Workers这个索引怎么用。打开wrangler.toml文件,在最后加上这几行:
[[vectorize]]
binding = "VECTORIZE_INDEX"
index_name = "my-search-index"binding是你在代码里调用索引的变量名,index_name要和刚才创建的索引名字一致。 验证一下 想确认索引创建成功,可以列出所有索引:
wrangler vectorize list应该能看到你刚才创建的my-search-index。 常见错误提示 我刚开始用的时候踩过几个坑,提前说说:
- 如果提示”Index already exists”,说明你之前创建过同名索引,换个名字或者用
wrangler vectorize delete删掉旧的 - 如果
wrangler.toml里忘了加[[vectorize]]配置,代码里调用env.VECTORIZE_INDEX会报”undefined”错误 - preset里的模型名不能写错,官方支持的模型列表可以在Cloudflare文档里找到 到这一步,索引就算建好了。下一步咱们写代码往里面塞数据、然后搜索。
写代码:30行实现语义搜索
重头戏来了!咱们用最简单的方式实现一个完整的语义搜索。我会把代码拆成几块讲,每一步都能跑通。 第一步:插入数据 假如你有几篇博客文章,想让用户能语义搜索。先把文章内容转成向量存进去。 打开src/index.ts,写入这段代码:
export interface Env {
VECTORIZE_INDEX: VectorizeIndex;
AI: Ai; // Cloudflare Workers AI
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const url = new URL(request.url);
// 插入数据的接口
if (url.pathname === '/insert') {
const articles = [
{
id: '1',
title: 'Cloudflare Workers入门',
content: 'Cloudflare Workers是一个无服务器计算平台,让你能在边缘节点运行代码'
},
{
id: '2',
title: 'Serverless架构指南',
content: 'Serverless computing让部署和扩展变得非常简单,你不用管服务器'
},
{
id: '3',
title: 'JavaScript异步编程',
content: 'Promise和async/await是处理异步操作的现代方式'
}
];
// 批量生成向量
const embeddings = await Promise.all(
articles.map(async (article) => {
const embedding = await env.AI.run('@cf/baai/bge-small-en-v1.5', {
text: `${article.title} ${article.content}`
});
return {
id: article.id,
values: embedding.data[0], // 768维向量
metadata: {
title: article.title,
content: article.content
}
};
})
);
// 插入到Vectorize
await env.VECTORIZE_INDEX.upsert(embeddings);
return new Response('插入成功!', { status: 200 });
}
return new Response('Not found', { status: 404 });
}
};这段代码干了啥?
- 定义了3篇示例文章
- 用Cloudflare的AI模型把每篇文章转成768维向量
- 调用
upsert方法把向量存进Vectorize索引 注意metadata字段,这里可以存原始的标题和内容,搜索时能直接拿到。 第二步:搜索查询 现在数据有了,咱们加个搜索接口:
// 在 fetch 函数里加上这段
if (url.pathname === '/search') {
const query = url.searchParams.get('q');
if (!query) {
return new Response('缺少查询参数 q', { status: 400 });
}
// 把查询文本转成向量
const queryEmbedding = await env.AI.run('@cf/baai/bge-small-en-v1.5', {
text: query
});
// 在索引里搜索最相似的5条
const results = await env.VECTORIZE_INDEX.query(queryEmbedding.data[0], {
topK: 5,
returnMetadata: true
});
// 格式化结果
const formattedResults = results.matches.map((match) => ({
id: match.id,
score: match.score, // 相似度分数,0-1之间
title: match.metadata?.title,
content: match.metadata?.content
}));
return new Response(JSON.stringify(formattedResults, null, 2), {
headers: { 'Content-Type': 'application/json' }
});
}这个接口干了啥?
- 接收查询参数
q(比如用户输入”无服务器”) - 把查询文本转成向量
- 调用
query方法找最相似的5条结果 - 返回带分数的搜索结果 第三步:本地测试 代码写完了,跑起来试试:
wrangler devWrangler会启动一个本地服务器,通常是http://localhost:8787。 先插入数据:
curl http://localhost:8787/insert看到”插入成功!“就OK了。 然后试试搜索:
curl "http://localhost:8787/search?q=无服务器平台"你应该能看到类似这样的结果:
[
{
"id": "1",
"score": 0.89,
"title": "Cloudflare Workers入门",
"content": "Cloudflare Workers是一个无服务器计算平台..."
},
{
"id": "2",
"score": 0.85,
"title": "Serverless架构指南",
"content": "Serverless computing让部署和扩展变得非常简单..."
}
]注意看score字段,这是相似度分数,越高越相关。虽然查询的是”无服务器平台”,但成功匹配到了”Cloudflare Workers”和”Serverless”相关的文章——这就是语义搜索的魔力! 代码说明 你可能会好奇几个点:
- 为啥不用OpenAI的API?Cloudflare Workers AI内置了嵌入模型,免费额度足够用,也不用管API密钥
- upsert是啥?就是”更新或插入”,如果ID已存在就更新,不存在就插入
- topK设置多少合适?一般5-10条就够了,太多了用户也看不过来 好了,到这里你已经掌握了80%的核心用法。接下来讲几个进阶技巧,让搜索更精准。
进阶技巧:3个优化建议
基础功能跑通了,但想要搜索效果更好,还有几个小技巧值得试试。 1. 元数据过滤:精准圈定搜索范围 假如你的博客有分类,比如”技术”、“生活”、“读书笔记”,用户搜索”Python”的时候肯定只想看技术类文章。这时候就用上元数据过滤了。 修改插入代码,给每篇文章加个分类:
metadata: {
title: article.title,
content: article.content,
category: 'tech' // 新增分类字段
}搜索的时候加上过滤条件:
const results = await env.VECTORIZE_INDEX.query(queryEmbedding.data[0], {
topK: 5,
returnMetadata: true,
filter: { category: 'tech' } // 只搜索技术类
});这样就能避免搜”Python”的时候跳出来”我养了一条蟒蛇”这种生活类文章了。 2. 混合搜索:语义+关键词双保险 有时候纯语义搜索会漏掉一些精确匹配的结果。比如搜”React 18”,你肯定希望标题里带”React 18”的文章排在前面。 这时候可以结合传统关键词筛选:
// 先做语义搜索
const vectorResults = await env.VECTORIZE_INDEX.query(queryEmbedding.data[0], {
topK: 20, // 多取点候选
returnMetadata: true
});
// 再做关键词过滤和加权
const finalResults = vectorResults.matches
.map((match) => {
let boostedScore = match.score;
// 如果标题完全匹配关键词,加分
if (match.metadata?.title.includes(query)) {
boostedScore += 0.2;
}
return { ...match, score: boostedScore };
})
.sort((a, b) => b.score - a.score)
.slice(0, 5); // 取前5条这种”语义找相关+关键词加权”的组合拳,能让搜索结果更精准。 3. 批量操作:提升性能 如果你要一次插入几百上千条数据,一条条insert会很慢。Vectorize支持批量操作,性能能提升好几倍。
// 把文章分批,每批100条
const batchSize = 100;
for (let i = 0; i < allArticles.length; i += batchSize) {
const batch = allArticles.slice(i, i + batchSize);
const embeddings = await Promise.all(
batch.map(async (article) => {
// ... 生成向量
})
);
await env.VECTORIZE_INDEX.upsert(embeddings);
}我之前导入500篇文章,单条插入花了20分钟,改成批量之后3分钟就搞定了。 还有个小技巧:如果你用Workers KV存了热门查询的结果,可以加个缓存层,重复查询直接从KV读,省得每次都跑向量计算。
第三部分:避坑指南
常见问题及解决方案
用Vectorize过程中我踩过不少坑,这里总结几个高频问题,能帮你少走弯路。 问题1:向量维度不匹配错误 报错信息:Dimension mismatch: expected 768, got 1536 原因很简单:你创建索引时用的是768维的模型(bge-small),但后来生成向量时换成了1536维的模型(比如OpenAI的text-embedding-3-small)。Vectorize要求同一个索引里所有向量维度必须一致。 解决办法:
- 方案一:重新创建索引,用和嵌入模型匹配的preset
- 方案二:换嵌入模型,保证维度对得上 我的建议是一开始就想好用哪个模型,别中途换。 问题2:免费额度到底够不够用 这是大家最关心的。Cloudflare官方没给特别明确的免费额度数字,但根据定价公式可以算出来: 存储:免费额度大概能存500万个768维向量 查询:每月大概300万次查询 听起来很多对吧?实际上对小项目完全够了。我的博客200篇文章,每天访问量300,搜索量大概30次,跑了一个月账单是0美元(在免费额度内)。 如果真超了免费额度,按量付费也便宜得离谱——100万向量查询3万次才0.31美元。 问题3:该选哪个嵌入模型 Cloudflare支持好几个内置模型,选哪个要看场景:
- 中文内容:
@cf/baai/bge-base-zh-v1.5(专门针对中文优化) - 英文内容:
@cf/baai/bge-small-en-v1.5(性能和成本平衡) - 多语言混合:
@cf/baai/bge-m3(支持100多种语言) 如果你追求极致效果,也可以用OpenAI的text-embedding-3-small(1536维),但要自己调用API,成本会高一点。 我的经验是:大部分情况Cloudflare内置的BGE模型就够用了,质量已经很不错。 问题4:从其他向量数据库迁移数据 假如你之前用的Pinecone,现在想省钱换Vectorize,怎么迁移数据? 思路很简单:
- 从Pinecone导出所有向量和metadata
- 转换成Vectorize的格式
- 批量upsert到新索引 我写了个简单的迁移脚本(伪代码):
// 从Pinecone获取所有向量
const pineconeVectors = await pineconeIndex.fetch({ ids: allIds });
// 转换格式
const vectorizeFormat = Object.entries(pineconeVectors.vectors).map(
([id, vector]) => ({
id,
values: vector.values,
metadata: vector.metadata
})
);
// 批量插入Vectorize
const batchSize = 100;
for (let i = 0; i < vectorizeFormat.length; i += batchSize) {
const batch = vectorizeFormat.slice(i, i + batchSize);
await env.VECTORIZE_INDEX.upsert(batch);
}注意:向量维度必须一致!如果Pinecone用的1536维,Vectorize索引也得用1536维的preset。 问题5:搜索结果不准怎么办 有时候搜索结果跟预期差很远,可能是这几个原因:
- 嵌入模型不适合你的领域:比如你做医疗内容,通用模型可能效果不好,考虑用领域专用模型
- 输入文本太短:向量需要足够的上下文才能准确表达语义,标题+摘要比只用标题效果好
- 没做数据清洗:文本里有大量HTML标签、特殊字符会影响向量质量 我的做法是:把标题、摘要、正文前200字合在一起生成向量,效果明显比只用标题好。
什么时候该升级方案
Vectorize虽然香,但不是万能的。有几种情况你可能需要考虑其他方案。 信号1:向量数超过500万 Vectorize目前单个索引最多支持500万向量。如果你的数据规模更大,比如电商平台有几千万商品,那就得考虑Pinecone或者自建Milvus集群了。不过说实话,大多数应用根本到不了这个量级。 信号2:需要多模态搜索 假如你除了文本还要搜索图片、音频、视频,Vectorize目前只支持文本向量。这种情况Weaviate是更好的选择,它原生支持多模态数据。 信号3:复杂的图数据库需求 如果你的应用需要结合知识图谱,比如”找出所有和XX相关的、发布在2024年的、作者是YY的文章”,这种复杂查询Vectorize不太够用。可以考虑GraphRAG方案,结合Neo4j这种图数据库和向量搜索。 信号4:对延迟要求极高 Vectorize的查询延迟一般在50-200ms,对大多数应用已经很快了。但如果你做实时推荐系统,要求10ms内返回结果,可能需要Redis + Faiss这种内存方案。 我的建议 别一上来就追求完美方案。先用Vectorize把功能跑通,验证产品方向。等业务真做大了、遇到瓶颈了,再考虑升级。过早优化是万恶之源,更何况迁移成本也不高——向量数据格式都差不多,写个脚本几小时就能搬完。 我见过不少人纠结选型纠结了一个月,最后项目还没开始做。不如先动手,有问题再调整。
结论
说了这么多,回到最开始那个问题:向量数据库到底贵不贵? 答案是:看你选什么。Pinecone最低50美元/月,但Vectorize的免费额度足够跑一个有一定规模的应用。我自己的博客语义搜索跑了两个月,账单还是0美元。 这篇文章从概念讲到实战,从基础用法讲到进阶技巧,希望能帮你快速上手Vectorize。如果你也想给自己的项目加上语义搜索功能,不妨试试看——30分钟就能跑通一个Demo,成本几乎为零,试错成本比点一杯咖啡还低。 下一步你可以做的:
- 参考Cloudflare官方示例,5分钟跑起来试试效果
- 加入Cloudflare Discord,有问题随时问
- 接入你自己的数据,做一个实用的应用——比如公司知识库搜索、个人笔记检索、智能客服机器人 语义搜索真的没那么难,关键是迈出第一步。等你真正用起来,就会发现这玩意儿确实能解决不少实际问题。 最后说一句,如果这篇文章帮到你了,不妨分享给也在折腾AI应用的朋友。大家一起省钱一起进步,何乐而不为呢?
发布于: 2025年12月1日 · 修改于: 2025年12月4日