AI知识库20分钟搭完?Workers AI + Vectorize手把手教你做RAG(附完整代码)
引言
想给公司做个智能客服,查了一圈 RAG 教程,要么讲理论云里雾里,要么让你先租个 GPU、搭环境,看着就头大。说实话,我刚开始研究这块的时候也一样,光是配置 LangChain 和向量数据库就折腾了两天,还没跑起来。 后来发现 Cloudflare 推出了一整套 AI 工具,Workers AI + Vectorize + D1,全托管的,免费额度还挺大方。我试着用它们搭了个笔记问答应用,从零到能用真的不到 20 分钟,代码也就百来行。 这篇文章会手把手带你走一遍完整流程:
- 先讲清楚 RAG 到底是什么(不扔术语,用大白话)
- 实战搭建一个能跑的知识库问答应用(有完整代码)
- 优化技巧让检索更准确、成本更低
- 部署上线真正用起来 你只需要懂点 JavaScript,有个 Cloudflare 账号(免费),跟着操作就能做出来。
RAG 是个啥?5 分钟看懂工作原理
用考试来理解 RAG
先说个直观的比喻。你考试的时候,闭卷考试只能靠脑子里记的东西答题,万一忘了就瞎编。开卷考试就不一样了,不确定的时候翻书查资料,答案准确多了。 RAG(检索增强生成)就是给 AI 开卷考试的权限。 传统 LLM 就像闭卷考试,只能基于训练时见过的数据回答。问题是:
- 训练数据有时效性,不知道最新动态
- 没见过你公司的内部文档
- 记不住所有细节,容易瞎编(行话叫”幻觉”) RAG 的做法是:先从你准备好的知识库里找相关资料,然后把资料给 AI,让它基于这些内容回答。这样答案既靠谱又能结合最新信息。
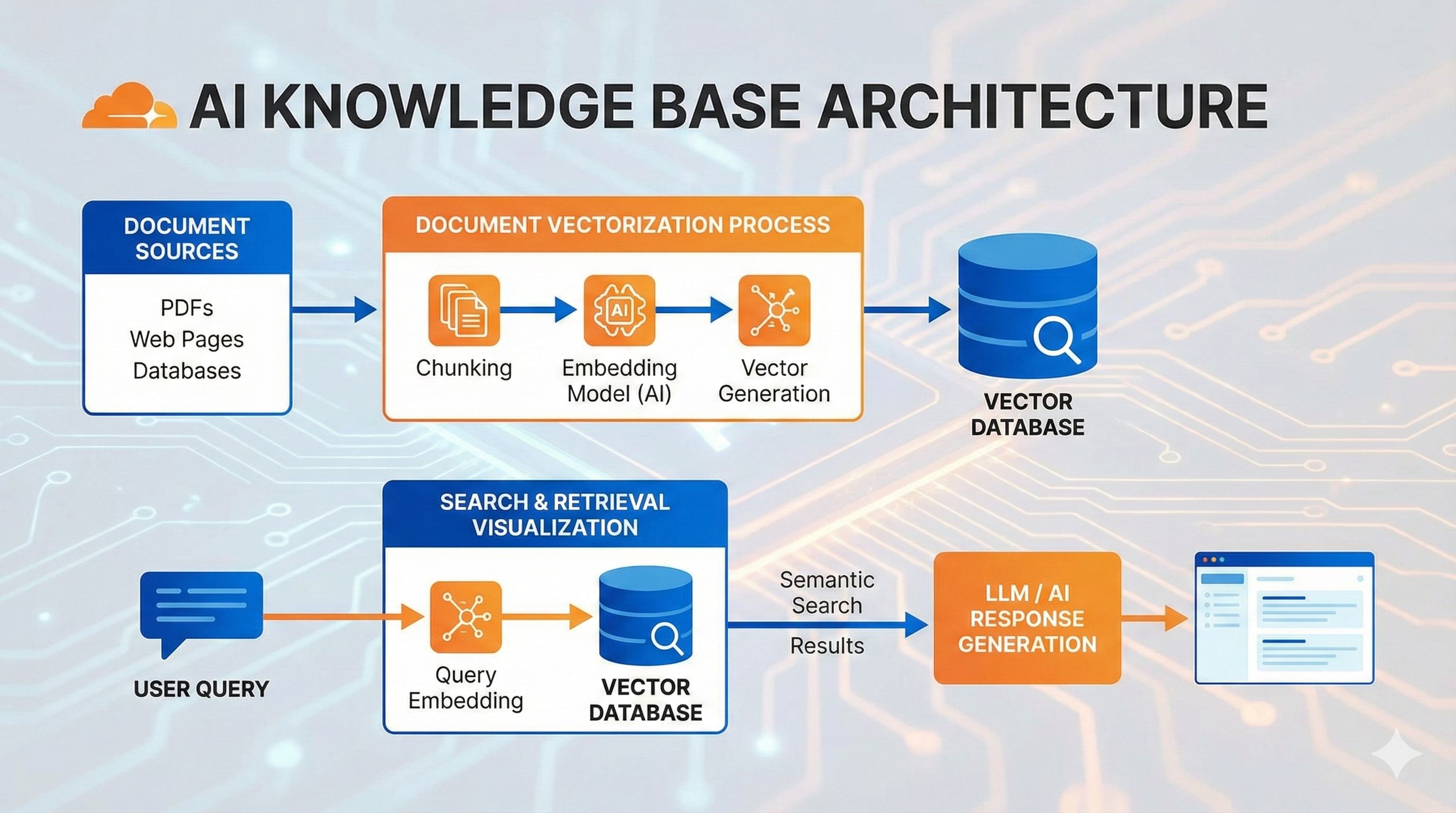
RAG 的三个核心步骤
整个流程其实就三步:
第一步:把知识变成向量存起来 你有一堆文档对吧?RAG 会把每段文字转成一串数字(专业术语叫”向量”或”Embedding”),这串数字代表了文字的语义。 打个比方,“猫很可爱”和”小猫萌萌的”虽然用词不同,但意思接近,转成向量后这两串数字也会很接近。这些向量会存到 Vectorize 这样的向量数据库里。
第二步:用户提问时,找出最相关的知识片段 用户问”怎么训练猫咪”的时候,系统会先把这个问题也转成向量,然后在数据库里找”距离最近”的那几段内容——也就是语义最相关的知识。 这个过程叫”相似度搜索”,速度很快,几毫秒就能从几万条数据里找出最匹配的 3-5 条。
第三步:把检索到的内容喂给 LLM 生成答案 找到相关内容后,组装成一个 Prompt 发给 AI:
以下是相关资料:
[检索到的内容1]
[检索到的内容2]
...
用户问题:怎么训练猫咪?
请基于上述资料回答。AI 看到这些”参考资料”,就能给出准确且有依据的答案了。
为什么选 Cloudflare 全家桶?
市面上做 RAG 的方案挺多,LangChain、LlamaIndex 啥的都行,但要自己配环境、挑向量数据库、管 GPU 资源,折腾起来挺累的。 Cloudflare 这套方案的优势是:
Workers AI - 内置十几个开源模型(Llama 3、Claude 等),调 API 就能用,不用租 GPU。免费层每天有固定的 Neurons 额度(计量单位),个人项目够用了。
Vectorize - 托管的向量数据库,不用自己搭 Milvus、Pinecone 那些。创建索引、插入向量、相似度搜索,几行代码搞定。
D1 - Cloudflare 的 SQLite 数据库,存原始文本用。向量数据库只存向量,具体文字内容还是要从这里取。
全托管 - 这是最爽的地方。不用操心服务器、扩容、备份这些破事,专心写代码就行。而且 Cloudflare 的边缘网络,全球访问都快。 2025 年 Cloudflare 还推出了 AutoRAG,进一步简化了流程——上传文档到 R2,后面的切分、向量化、检索、生成全自动。不过这篇文章咱们还是手动搭一遍,这样能学到底层原理。 说了这么多理论,接下来动手做一个。
动手实战 - 搭建你的第一个 RAG 应用
咱们做个笔记问答应用:用户可以添加笔记,然后提问,系统从所有笔记里找相关内容回答。
项目初始化和环境准备
先装 Wrangler(Cloudflare 的 CLI 工具):
npm install -g wrangler
wrangler login # 登录你的 Cloudflare 账号创建项目:
npm create cloudflare@latest rag-notes-app
# 选择 "Hello World" worker
# 选择 TypeScript
cd rag-notes-app装个路由库 Hono(比原生 Workers API 好用):
npm install hono创建 D1 数据库和 Vectorize 索引:
# 创建 D1 数据库存原始笔记
wrangler d1 create notes-db
# 创建 Vectorize 索引(768 维,配合 bge-base-en-v1.5 模型)
wrangler vectorize create notes-index --dimensions=768 --metric=cosine然后配置 wrangler.jsonc(或 wrangler.toml):
{
"name": "rag-notes-app",
"main": "src/index.ts",
"compatibility_date": "2024-01-01",
"node_compat": true,
// AI 绑定
"ai": {
"binding": "AI"
},
// D1 数据库绑定
"d1_databases": [
{
"binding": "DB",
"database_name": "notes-db",
"database_id": "你的数据库ID" // 从上面创建命令的输出复制
}
],
// Vectorize 索引绑定
"vectorize": [
{
"binding": "VECTORIZE",
"index_name": "notes-index"
}
],
// Workflow 绑定(处理异步向量化任务)
"workflows": [
{
"binding": "RAG_WORKFLOW",
"name": "rag-workflow",
"class_name": "RAGWorkflow"
}
]
}初始化数据库表:
-- schema.sql
CREATE TABLE IF NOT EXISTS notes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);运行:
wrangler d1 execute notes-db --file=./schema.sql实现知识库录入功能
这是整个 RAG 的核心——把用户的笔记转成向量存起来。 创建 src/workflow.ts(Workflow 处理异步任务):
import { WorkflowEntrypoint, WorkflowStep } from 'cloudflare:workers';
type Env = {
AI: Ai;
DB: D1Database;
VECTORIZE: VectorizeIndex;
};
type Params = {
noteId: number;
text: string;
};
export class RAGWorkflow extends WorkflowEntrypoint<Env, Params> {
async run(event: WorkflowEvent<Params>, step: WorkflowStep) {
const { noteId, text } = event.payload;
// 步骤1:确认 D1 记录已创建(由主路由完成)
// 步骤2:生成向量
const embeddings = await step.do('generate embeddings', async () => {
const response = await this.env.AI.run(
'@cf/baai/bge-base-en-v1.5', // 768维的 Embedding 模型
{ text: [text] }
);
return response.data[0]; // 返回向量数组
});
// 步骤3:插入 Vectorize
await step.do('insert vector', async () => {
await this.env.VECTORIZE.insert([
{
id: noteId.toString(),
values: embeddings,
metadata: { text } // 存一份文本方便调试
}
]);
});
}
}主路由 src/index.ts(处理添加笔记):
import { Hono } from 'hono';
import { RAGWorkflow } from './workflow';
type Bindings = {
AI: Ai;
DB: D1Database;
VECTORIZE: VectorizeIndex;
RAG_WORKFLOW: Workflow;
};
const app = new Hono<{ Bindings: Bindings }>();
// 添加笔记
app.post('/notes', async (c) => {
const { text } = await c.req.json<{ text: string }>();
if (!text?.trim()) {
return c.json({ error: 'Text is required' }, 400);
}
// 插入 D1
const result = await c.env.DB.prepare(
'INSERT INTO notes (text) VALUES (?) RETURNING id'
).bind(text).first<{ id: number }>();
if (!result) {
return c.json({ error: 'Failed to create note' }, 500);
}
// 触发 Workflow 异步生成向量
await c.env.RAG_WORKFLOW.create({
params: { noteId: result.id, text }
});
return c.json({
id: result.id,
message: 'Note created, vectorization in progress'
});
});
export default app;
export { RAGWorkflow };这样一来,用户发 POST 请求添加笔记时:
- 文本立即存到 D1
- 后台 Workflow 慢慢生成向量、插入 Vectorize
- 就算向量化要几秒钟,也不会阻塞用户请求
实现智能问答功能
现在可以存笔记了,接下来做查询。 在 src/index.ts 添加:
// 查询问答
app.get('/', async (c) => {
const query = c.req.query('q');
if (!query) {
return c.json({ error: 'Query parameter "q" is required' }, 400);
}
// 第一步:把问题转成向量
const queryEmbedding = await c.env.AI.run(
'@cf/baai/bge-base-en-v1.5',
{ text: [query] }
);
// 第二步:在 Vectorize 里找最相似的 3 条笔记
const matches = await c.env.VECTORIZE.query(
queryEmbedding.data[0],
{ topK: 3, returnMetadata: true }
);
if (matches.count === 0) {
return c.json({ answer: '没有找到相关笔记' });
}
// 第三步:从 D1 获取完整文本(如果需要)
const noteIds = matches.matches.map(m => m.id);
const notes = await c.env.DB.prepare(
`SELECT text FROM notes WHERE id IN (${noteIds.map(() => '?').join(',')})`
).bind(...noteIds).all();
// 第四步:构造 Prompt,调用 LLM 生成答案
const context = notes.results.map((n: any) => n.text).join('\n\n---\n\n');
const prompt = `以下是相关的笔记内容:
${context}
用户问题:${query}
请基于上述笔记内容回答用户问题。如果笔记中没有相关信息,请说明。`;
const aiResponse = await c.env.AI.run(
'@cf/meta/llama-3-8b-instruct', // 或者用 claude-3-5-sonnet-latest
{
messages: [
{ role: 'system', content: '你是一个智能笔记助手' },
{ role: 'user', content: prompt }
]
}
);
return c.json({
answer: aiResponse.response,
sources: matches.matches.map(m => ({
id: m.id,
score: m.score,
text: m.metadata?.text
}))
});
});测试一下:
# 本地运行
wrangler dev
# 添加笔记
curl -X POST http://localhost:8787/notes \
-H "Content-Type: application/json" \
-d '{"text": "Cloudflare Workers AI 支持 Llama 3 和 Claude 模型"}'
curl -X POST http://localhost:8787/notes \
-H "Content-Type: application/json" \
-d '{"text": "Vectorize 使用余弦相似度进行向量检索"}'
# 等几秒让 Workflow 完成向量化
# 提问
curl "http://localhost:8787/?q=Workers%20AI%20有哪些模型"如果一切正常,你会收到基于笔记内容的回答。
删除和更新功能
删除笔记时,记得同时删除 D1 和 Vectorize 的数据:
app.delete('/notes/:id', async (c) => {
const id = c.req.param('id');
// 从 D1 删除
await c.env.DB.prepare('DELETE FROM notes WHERE id = ?').bind(id).run();
// 从 Vectorize 删除
await c.env.VECTORIZE.deleteByIds([id]);
return c.json({ message: 'Note deleted' });
});更新的话,最简单的方式是先删后加(重新生成向量)。 完整代码可以参考 Cloudflare 官方示例。
进阶优化 - 让你的 RAG 更聪明
基础功能跑起来了,但要真正用在实际项目里,还有些细节值得优化。
文本分块策略
现在咱们是把整条笔记当一个单元存的。如果笔记很长(比如一篇技术文档),这样做会有问题:
- 检索时整篇文档的相似度可能不高(只有部分段落相关)
- Prompt 太长会超出 LLM 的上下文窗口限制 更好的做法是把长文本切成小块(chunk),每块单独生成向量。 简单的分块方法:
function splitText(text: string, chunkSize: number = 500, overlap: number = 50): string[] {
const chunks: string[] = [];
let start = 0;
while (start < text.length) {
const end = Math.min(start + chunkSize, text.length);
chunks.push(text.slice(start, end));
start = end - overlap; // 重叠一点,避免句子被切断
}
return chunks;
}更智能的方式是按段落或语义分割(可以用 LangChain 的 RecursiveCharacterTextSplitter),不过对大部分场景来说,固定长度+重叠已经够用了。 修改 Workflow,给每个 chunk 分配唯一 ID:
const chunks = splitText(text);
for (let i = 0; i < chunks.length; i++) {
const chunkId = `${noteId}-${i}`;
const embeddings = await this.env.AI.run('@cf/baai/bge-base-en-v1.5', {
text: [chunks[i]]
});
await this.env.VECTORIZE.insert([{
id: chunkId,
values: embeddings.data[0],
metadata: { noteId, chunkIndex: i, text: chunks[i] }
}]);
}提升检索准确度
调整 topK 和相似度阈值 默认返回 top 3 可能不够,也可能太多。试试调到 5 条,同时过滤掉相似度太低的:
const matches = await c.env.VECTORIZE.query(queryEmbedding.data[0], {
topK: 5,
returnMetadata: true
});
// 只保留相似度 > 0.7 的结果
const relevantMatches = matches.matches.filter(m => m.score > 0.7);相似度分数范围是 0-1(余弦相似度),0.7 以上一般算比较相关。 优化 Prompt 别光把检索到的内容扔给 AI,告诉它怎么用这些信息:
const prompt = `你是一个智能笔记助手。以下是从笔记库中检索到的相关内容(按相关性排序):
${context}
请严格基于上述内容回答用户问题。如果内容不足以回答问题,明确说明"笔记中没有找到相关信息",不要编造答案。
用户问题:${query}`;关键点:
- 明确告诉 AI 这是检索到的资料
- 要求它只基于这些内容回答
- 允许它承认”不知道” 这样能减少 AI 瞎编的情况。
成本控制和限流
Workers AI 免费层每天有 Neurons 额度限制(具体数值会变,去 Pricing 页面 查最新的)。
监控用量: 在 Cloudflare Dashboard → Workers AI 里能看到每日消耗。不同模型消耗不同,Embedding 模型便宜,LLM 生成贵一些。
降级策略: 如果担心超额,可以:
- 限制每个用户的请求频率(用 KV 或 Durable Objects 计数)
- 超出额度后改用更小的模型或返回缓存结果
- 对于非关键请求,直接返回检索到的原文,不调 LLM
// 简单限流示例
const userKey = c.req.header('X-User-ID') || 'anonymous';
const requestCount = await c.env.KV.get(`rate:${userKey}`) || 0;
if (requestCount > 100) {
return c.json({ error: 'Rate limit exceeded' }, 429);
}
await c.env.KV.put(`rate:${userKey}`, requestCount + 1, { expirationTtl: 86400 });切换更强的模型
Llama 3 8B 已经挺不错了,但如果想要更好的理解能力,可以试试 Claude:
// 需要先在 Dashboard 绑定 Anthropic API key
const aiResponse = await c.env.AI.run('claude-3-5-sonnet-latest', {
messages: [
{ role: 'system', content: '你是一个智能笔记助手' },
{ role: 'user', content: prompt }
]
});Claude 的理解能力和输出质量确实更好,但消耗的 Neurons 也更多。根据实际需求选吧。 我自己的经验是:
- 简单问答:Llama 3 够用
- 需要推理、总结:Claude 明显好一些
- 预算有限:先用 Llama 测试,确定需求后再升级
部署上线和实际应用场景
部署流程
本地测试没问题后,部署超简单:
wrangler deploy就这一行,Cloudflare 会自动:
- 打包你的代码
- 部署到全球边缘节点
- 生成一个
.workers.dev域名 你会看到类似这样的输出:
Published rag-notes-app
https://rag-notes-app.your-account.workers.dev这就是你的 API 地址了。
绑定自定义域名(可选): 如果你有域名托管在 Cloudflare,可以绑定:
wrangler domains add api.yourdomain.com或者在 Dashboard → Workers & Pages → 你的 Worker → Settings → Domains 里添加。
环境变量和 Secrets: 如果你用了 Anthropic API key 或其他敏感信息:
wrangler secret put ANTHROPIC_API_KEY
# 输入你的 key代码里这样用:
const apiKey = c.env.ANTHROPIC_API_KEY;真实应用场景
这套 RAG 架构能做的事挺多,分享几个实际场景:
1. 企业知识库问答
场景:公司有几百页员工手册、技术文档、FAQ,新员工找资料很麻烦。 做法:
- 把所有文档上传,按章节分块存入 Vectorize
- 做个简单的 Web 界面或接入企业微信机器人
- 员工直接问”报销流程是什么”,系统自动检索相关章节回答 好处:24 小时在线,比翻文档快多了。
2. 智能客服
场景:电商网站有大量商品信息和售后政策,客服重复回答相同问题。 做法:
- 把常见问题、商品描述、退换货政策存进去
- 用户咨询时先让 RAG 系统回答
- 答不上来的再转人工 效果:某个开发者用这套方案,把客服压力减少了 60%+。
3. 个人笔记助手
场景:你用 Notion 或 Obsidian 记了几年笔记,想快速找到某个知识点。 做法:
- 定期把笔记导出,通过 API 添加到 RAG 系统
- 需要时直接问”上次看的那个 TypeScript 技巧是啥来着”
- 系统检索出相关笔记片段 我自己就在用类似的工具,找资料效率真的提升了不少。
4. “Chat with PDF” 工具
场景:用户上传一份 PDF(论文、合同、报告),想快速提取信息。 做法(参考 Rohit Patil 的案例):
- 用户上传 PDF 到 R2
- Worker 读取 PDF,提取文本,分块向量化
- 用户可以问”这份合同的付款条款是什么” 这个场景特别实用,很多法律、咨询行业的人需要。
常见问题排查
问题1:向量维度不匹配
错误:dimension mismatch: expected 768, got 512 原因:Vectorize 索引创建时设的维度(768)和模型输出的维度不一致。 解决:确保索引维度和模型匹配。bge-base-en-v1.5 是 768 维,别用错模型。
问题2:D1 和 Vectorize 数据不一致
现象:查询返回的 note ID 在 D1 里不存在。 原因:可能删除 D1 记录时忘了删 Vectorize,或者 Workflow 失败了。 解决:删除操作要么包在事务里,要么用 Workflow 确保两边都删干净。
问题3:Workflow 超时
错误:workflow execution timeout 原因:向量化大量文本时超过 Workflow 的时间限制。 解决:把大文档拆成多个 Workflow 任务,或者批量处理。
// 分批处理
const batchSize = 10;
for (let i = 0; i < chunks.length; i += batchSize) {
const batch = chunks.slice(i, i + batchSize);
await c.env.RAG_WORKFLOW.create({
params: { noteId, chunks: batch, offset: i }
});
}结论
说了这么多,回顾一下咱们做了啥:
- 弄懂了 RAG 原理:检索增强生成,就是给 AI 开卷考试的权限,先找资料再回答
- 搭了个能跑的应用:笔记问答系统,从环境准备到代码实现,完整走了一遍
- 学了优化技巧:文本分块、检索调优、成本控制,这些细节让应用真正可用
- 看了实际场景:企业知识库、智能客服、个人助手、PDF 聊天,都是可以落地的方向 Cloudflare 这套方案最大的优势是门槛低。不用租 GPU、不用搭数据库、不用操心运维,免费额度对个人项目来说绝对够用。就算是生产环境,付费计划也比自建便宜多了。 接下来你可以:
- 立即动手:克隆 官方示例代码,
wrangler dev跑起来,5 分钟就能看到效果 - 接入真实数据:把你的笔记、文档、FAQ 导进去,看看检索质量如何
- 做个前端界面:用 React/Vue 做个简单的聊天界面,或者直接用 Cloudflare Pages 部署
- 探索更多可能:试试多模态 RAG(结合图片、表格)、GraphRAG(知识图谱增强)等高级玩法 RAG 是当前 AI 应用最实用的架构之一,掌握它能让你做出很多有意思的东西。试下来,Cloudflare 全家桶确实能解决不少实际问题。 要是碰到问题,可以去 Cloudflare Discord 或 Community 论坛 问,社区挺活跃的。
发布于: 2025年12月1日 · 修改于: 2025年12月4日