実践ガイド:Gemini Multimodal Live API を活用した低遅延な音声を伴う AI アシスタントの構築
正直なところ、Gemini から Live API が出たと初めて聞いたとき、私は少し懐疑的でした。「また新しい API か、これまでのテキストインターフェースと似たようなものじゃないか?」と。しかし、実際に使ってみたところ、大げさではなく、新しい世界の扉が開いたような感覚を覚えました。今日はこの API を使って、本当にリアルタイムで対話できる AI アシスタントを構築する方法を共有します。
Gemini Multimodal Live API とは?
まず、前提を整理しましょう。従来の Gemini API はどのように動作していましたか?あなたがテキストを送り、モデルがテキストを返す。シンプルで直接的です。しかし、音声でやり取りしたい場合は、自分自身で ASR(音声認識)と TTS(音声合成)を組み込む必要があり、変換を繰り返すうちに、どうしても遅延(レイテンシ)が大きくなっていました。
Gemini Multimodal Live API の異なる点は、ネイティブで音声の入出力をサポートしていることです。つまり、マイクで収集した音声をそのまま投げることができ、返ってくるのも純粋なオーディオストリームです。中間でフォーマット変換を行う必要がありません。このエンドツーエンドの設計により、遅延を 500ms 以内に抑え込むことが可能になりました。
私はスマートホーム・プロジェクトでこの機能を試したことがあります。ユーザーが「リビングのライトを少し暗くして」と言うと、AI は言葉が終わるのとほぼ同時に反応を返しました。その流暢さは、相手がプログラムであることを忘れさせるほどでした。
現在サポートされているモデルは gemini-2.0-flash-native-audio-preview です。Google は急速に開発を進めているため、このバージョン番号には注意し、定期的に更新をチェックすることをお勧めします。
アーキテクチャ設計と技術選定
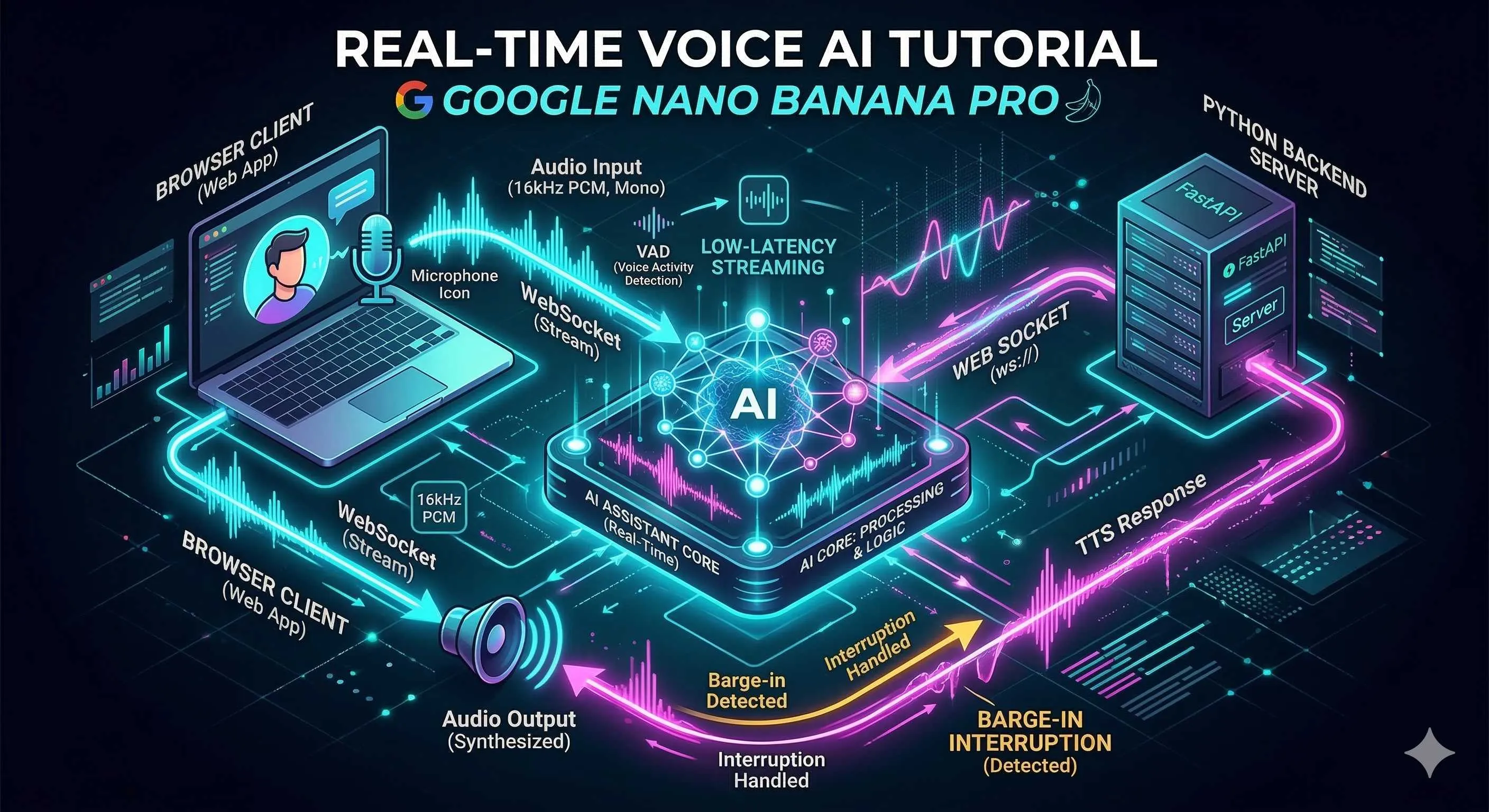
さて、このシステムをどのように構築するかを解説します。私のお勧めは、フロントエンドとバックエンドを分離したアーキテクチャです。理由は単純で、API キーをフロントエンドに露出させてはいけないからです。
全体のデータフローは以下のようになります。
[ブラウザ] --WebSocket--> [Pythonバックエンドプロキシ] --WebSocket--> [Gemini Live API]
| | |
マイク収集 転送 + ビジネスロジック AI処理
スピーカー再生 VAD検知 / 割り込み制御 音声生成「ブラウザから直接 Gemini に接続すればいいのではないか?」と思うかもしれません。技術的には可能ですが、それは API キーを JavaScript 内に書き込むことを意味し、開発者ツールを開けば誰でもあなたのキーを盗める状態になります。私は一度これをやってしまい、翌日の請求額が大変なことになった苦い経験があります。
そのため、技術スタックは以下のように決定しました。
| レイヤー | 技術 | 用途 |
|---|---|---|
| フロント | 素の JavaScript + Web Audio API | 音声収集、再生、AudioWorklet によるリアルタイム処理 |
| バック | Python 3.9+ + websockets ライブラリ | WebSocket プロキシ、VAD 検知、セッション管理 |
| プロトコル | WebSocket + JSON | Gemini との双方向通信 |
Web Audio API の AudioWorklet は非常に有用です。メインスレッドをブロックすることなく、独立したスレッドで音声を処理できます。実装コードは後ほど示します。
WebSocket 接続の確立とセッション管理
では、コードを書いていきましょう。まず解決すべきは、Gemini のサービスへの接続方法です。
Live API の WebSocket エンドポイントは以下の通りです。
wss://generativelanguage.googleapis.com/ws/google.ai.generativelanguage.v1alpha.GenerativeService.BidiGenerateContent?key=YOUR_API_KEYv1alpha という表記からも分かる通り、これはまだプレビュー版です。インターフェースが変更される可能性があるため、本番環境で使用する場合は注意が必要です。
接続が確立されたら、最初に行うべきことは Setup メッセージの送信です。どのように対話したいかを Gemini に伝えます。
import asyncio
import json
import websockets
GEMINI_API_KEY = "your-api-key-here"
GEMINI_WS_URL = (
f"wss://generativelanguage.googleapis.com/ws/"
f"google.ai.generativelanguage.v1alpha.GenerativeService.BidiGenerateContent"
f"?key={GEMINI_API_KEY}"
)
CONFIG = {
"setup": {
"model": "models/gemini-2.0-flash-native-audio-preview",
"generation_config": {
"response_modalities": ["AUDIO"],
"speech_config": {
"voice_config": {
"prebuilt_voice_config": {
"voice_name": "Charon" # 選択肢: Charon, Aoede など
}
}
}
},
"system_instruction": {
"parts": [{"text": "あなたは helpful な AI アシスタントです。簡潔で自然な回答を心がけてください。"}]
}
}
}
async def connect():
async with websockets.connect(GEMINI_WS_URL) as ws:
# setup 設定を送信
await ws.send(json.dumps(CONFIG))
# setup complete レスポンスを待機
response = await ws.recv()
data = json.loads(response)
if "setupComplete" in data:
print("✅ 接続確立成功。対話を開始できます。")
return ws
else:
raise Exception(f"Setup 失敗: {data}")ここでいくつかのパラメータについて説明します。
response_modalities:["AUDIO"]に設定すると、音声による返答のみを求めます。テキストも必要な場合は["AUDIO", "TEXT"]に変更します。voice_name: Gemini はいくつかのプリセット音声を提供しています。私は落ち着いたトーンのCharonが好みです。
接続断絶後の再接続については、いきなり猛烈にリトライするのではなく、指数バックオフ戦略を採用することをお勧めします。
async def connect_with_retry(max_retries=5):
for attempt in range(max_retries):
try:
return await connect()
except Exception as e:
wait_time = min(2 ** attempt, 30) # 最大30秒待機
print(f"接続失敗 ({e})。{wait_time}秒後に再試行します...")
await asyncio.sleep(wait_time)
raise Exception("複数回の試行後も接続できませんでした。")16kHz PCM オーディオストリームの収集と転送
接続ができたら、次は音声をどこから取得し、どう届けるかという問題です。
なぜ 16kHz を選ぶのか。人間の声の周波数範囲は一般に 85Hz から 255Hz 程度(男性は低め、女性は高め)です。ナイキストのサンプリング定理によれば、理論上は 8kHz で十分です。しかし、実際にはディテールを保持するために 16kHz が「スイートスポット(sweet spot)」となります。音質を担保しつつ、データ量を抑えられるからです。Gemini 公式もこのサンプリングレートを推奨しています。
フロントエンドの収集コードは以下のようになります。
class AudioRecorder {
constructor() {
this.sampleRate = 16000;
this.bufferSize = 1024;
this.audioContext = null;
this.workletNode = null;
this.stream = null;
this.onAudioData = null; // コールバック関数
}
async start() {
// マイク権限をリクエスト
this.stream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: 16000,
channelCount: 1,
echoCancellation: true,
noiseSuppression: true
}
});
// AudioContext を作成。サンプリングレートを強制指定
this.audioContext = new AudioContext({
sampleRate: 16000
});
// AudioWorklet プロセッサをロード
await this.audioContext.audioWorklet.addModule('pcm-processor.js');
const source = this.audioContext.createMediaStreamSource(this.stream);
this.workletNode = new AudioWorkletNode(this.audioContext, 'pcm-processor');
// オーディオデータを処理
this.workletNode.port.onmessage = (event) => {
const float32Data = event.data;
// Int16 PCM に変換
const int16Data = this.float32ToInt16(float32Data);
// Base64 エンコードして送信
const base64Data = btoa(String.fromCharCode(...new Uint8Array(int16Data.buffer)));
if (this.onAudioData) {
this.onAudioData(base64Data);
}
};
source.connect(this.workletNode);
console.log('🎤 音声収集を開始しました');
}
float32ToInt16(float32Array) {
const int16Array = new Int16Array(float32Array.length);
for (let i = 0; i < float32Array.length; i++) {
// Float32 (-1.0 ~ 1.0) -> Int16 (-32768 ~ 32767)
const s = Math.max(-1, Math.min(1, float32Array[i]));
int16Array[i] = s < 0 ? s * 0x8000 : s * 0x7FFF;
}
return int16Array;
}
stop() {
if (this.workletNode) {
this.workletNode.disconnect();
}
if (this.audioContext) {
this.audioContext.close();
}
if (this.stream) {
this.stream.getTracks().forEach(track => track.stop());
}
console.log('🛑 音声収集を停止しました');
}
}AudioWorklet 用の独立したファイル pcm-processor.js が必要です。
// pcm-processor.js
class PCMProcessor extends AudioWorkletProcessor {
process(inputs, outputs, parameters) {
const input = inputs[0];
if (input && input[0]) {
// メインスレッドへ送信
this.port.postMessage(input[0].slice());
}
return true; // プロセッサをアクティブに保つ
}
}
registerProcessor('pcm-processor', PCMProcessor);バックエンドでデータを受け取ったら、Gemini へ転送します。
async def send_audio(ws, base64_pcm_data):
"""オーディオデータを Gemini へ送信"""
message = {
"realtime_input": {
"media_chunks": [{
"mime_type": "audio/pcm;rate=16000",
"data": base64_pcm_data
}]
}
}
await ws.send(json.dumps(message))注意点として、一部のブラウザの getUserMedia は指定した sampleRate を無視し、実際には 44.1kHz や 48kHz を返すことがあります。念のため、AudioContext 内でリサンプリング(resample)するか、audiobuffer-to-wav のようなライブラリを利用して処理することをお勧めします。
VAD(音声活動検知)の実装
ここで問題が発生します。すべてのオーディオデータを無条件に送ると、無音の間もデータを送信することになり、帯域とコストの無駄遣いになります。そこで VAD(Voice Activity Detection:音声活動検知)の出番です。
VAD の役割は単純です。音声データの中に人が話している部分があるかどうかを判断することです。話している時だけ送り、そうでない時は休止します。
Google がオープンソースとして提供している WebRTC VAD は軽量で高速、かつ精度も良いためお勧めです。Python には webrtcvad というライブラリがあります。
import webrtcvad
import collections
import numpy as np
class VADProcessor:
def __init__(self, aggressiveness=2, frame_duration_ms=20):
"""
aggressiveness: 0-3。数値が高いほど厳格(誤検知を減らす)
frame_duration_ms: 10, 20, または 30
"""
self.vad = webrtcvad.Vad(aggressiveness)
self.frame_duration_ms = frame_duration_ms
self.sample_rate = 16000
# スムージング用のリングバッファ
self.ring_buffer = collections.deque(maxlen=30) # 600ms分
self.triggered = False
def process_frame(self, pcm_bytes):
"""
1フレームの音声を処理し、送信が必要かどうかを返す
"""
is_speech = self.vad.is_speech(pcm_bytes, self.sample_rate)
if not self.triggered:
# 非発火状態:音声を蓄積
self.ring_buffer.append((pcm_bytes, is_speech))
num_voiced = sum(1 for _, speech in self.ring_buffer if speech)
# バッファの 90% が音声なら発火
if num_voiced > 0.9 * self.ring_buffer.maxlen:
self.triggered = True
# バッファ内のデータをまとめて送信
return b''.join([f for f, _ in self.ring_buffer])
return None
else:
# 発火状態
if is_speech:
self.ring_buffer.append((pcm_bytes, True))
return pcm_bytes
else:
self.ring_buffer.append((pcm_bytes, False))
num_unvoiced = sum(1 for _, speech in self.ring_buffer if not speech)
# 90% が無音なら発火終了
if num_unvoiced > 0.9 * self.ring_buffer.maxlen:
self.triggered = False
self.ring_buffer.clear()
return pcm_bytes使用方法は以下の通りです。
vad = VADProcessor(aggressiveness=2)
async def handle_client_audio(websocket, gemini_ws):
async for message in websocket:
data = json.loads(message)
if 'audio' in data:
pcm_bytes = base64.b64decode(data['audio'])
# VAD 検知
result = vad.process_frame(pcm_bytes)
if result:
# 音声あり。Gemini へ転送
await send_audio(gemini_ws, base64.b64encode(result).decode())aggressiveness パラメータの調整は重要です。低すぎると背景ノイズを音声と誤解し、高すぎると小さな声を拾い損ねます。まずは 2 から始めて微調整することをお勧めします。
環境によって webrtcvad が使えない場合は、フロントエンドで RMS エネルギー量に基づいた簡易検知を行うこともできます。
// フロントエンドの代替案:RMSエネルギーに基づく簡易検知
function detectVoiceActivity(audioData, threshold = 0.015) {
const sum = audioData.reduce((acc, val) => acc + val * val, 0);
const rms = Math.sqrt(sum / audioData.length);
return rms > threshold;
}Barge-in(割り込み)機能の実装
音声アシスタントと会話している際、相手が長く話し続けていて、自分の言葉を挟めない時にもどかしさを感じたことはありませんか?
Barge-in(割り込み)機能はこれを解決します。AI が話している最中にユーザーが話し始めたら、AI は即座に発話を停止し、ユーザーの言葉に耳を傾けます。
嬉しいことに、Gemini Live API はネイティブでこの機能をサポートしており、しかも非常にインテリジェントです。設定で自動活動検知を有効にするだけです。
CONFIG = {
"setup": {
"model": "models/gemini-2.0-flash-native-audio-preview",
"generation_config": {
"response_modalities": ["AUDIO"],
},
"realtime_input_config": {
"automatic_activity_detection": {
"disabled": False,
"start_of_speech_sensitivity": "START_SENSITIVITY_HIGH",
"end_of_speech_sensitivity": "END_SENSITIVITY_LOW"
}
}
}
}sensitivity 設定の役割:
start_of_speech_sensitivityをHIGHにすると、ユーザーの話し始めに対して AI がより敏感になり、割り込みが起きやすくなります。end_of_speech_sensitivityをLOWにすると、AI はユーザーが本当に話し終えたかどうかを慎重に判断するようになり、誤判定を減らせます。
クライアント側では、interrupted イベントをリッスンし、即座にオーディオの再生を停止させる必要があります。
class GeminiClient {
constructor() {
this.audioQueue = [];
this.isPlaying = false;
this.currentSource = null;
}
async handleMessage(event) {
const message = JSON.parse(event.data);
// 割り込み信号を処理
if (message.server_content?.interrupted) {
console.log('⚡ ユーザーの割り込み。再生を停止します。');
this.stopPlayback();
return;
}
// AI から返った音声を処理
if (message.server_content?.model_turn) {
const parts = message.server_content.model_turn.parts;
for (const part of parts) {
if (part.inline_data?.mime_type.startsWith('audio/')) {
const audioData = base64ToArrayBuffer(part.inline_data.data);
this.queueAudio(audioData);
}
}
}
}
stopPlayback() {
// 再生キューをクリア
this.audioQueue = [];
this.isPlaying = false;
// 現在再生中の音声を停止
if (this.currentSource) {
try {
this.currentSource.stop();
} catch (e) {
// すでに停止している場合もある
}
this.currentSource = null;
}
}
async queueAudio(audioData) {
this.audioQueue.push(audioData);
if (!this.isPlaying) {
this.playNext();
}
}
async playNext() {
if (this.audioQueue.length === 0) {
this.isPlaying = false;
return;
}
this.isPlaying = true;
const audioData = this.audioQueue.shift();
// デコードして再生
const audioBuffer = await this.audioContext.decodeAudioData(audioData.slice());
this.currentSource = this.audioContext.createBufferSource();
this.currentSource.buffer = audioBuffer;
this.currentSource.connect(this.audioContext.destination);
this.currentSource.onended = () => {
this.playNext();
};
this.currentSource.start();
}
}注意点として、すでに自然に再生が終わっている場合に stop() を呼ぶと例外が投げられることがあるため、try-catch で囲い、コンソールがエラーで埋まらないようにしています。
パフォーマンス最適化と遅延制御
最後に、システムの遅延を最小限に抑える方法についてお話しします。
遅延の原因を理解しましょう。
- ネットワーク転送:ブラウザからサーバー、そして Gemini までの往復時間(RTT)
- 音声のエンコード/デコード:PCM 圧縮・展開の時間(PCM 自体は無損失なのでコストは小さい)
- バッファ蓄積:再生を滑らかにするためにあえて設けるバッファの深さ
これらに対し、私の経験に基づく最適化手法は以下の通りです。
バッファの深さを減らす
再生用バッファは大きすぎないように設定します。通常 100〜200ms もあれば十分です。
// 小さなバッファを設定
const audioContext = new AudioContext({
sampleRate: 16000,
latencyHint: 'interactive' // 低遅延モード
});アダプティブ・バッファ(適応型バッファ)
ネットワークの揺らぎ(ジッター)が大きい場合はバッファを少し増やし、安定しているときは減らすといった制御を行います。
エコーキャンセル
ユーザーがヘッドセットではなくスピーカーを使っている場合、AI の声がマイクに入り込み、ループしてしまいます。幸い、getUserMedia には標準でエコーキャンセル機能が備わっています。
navigator.mediaDevices.getUserMedia({
audio: {
echoCancellation: true,
noiseSuppression: true,
autoGainControl: true
}
})メトリクスの監視
最適化の効果を測定するために、Performance API を使って計測します。
class LatencyMonitor {
constructor() {
this.metrics = [];
}
recordSendTime() {
this.lastSendTime = performance.now();
}
recordReceiveTime() {
const latency = performance.now() - this.lastSendTime;
this.metrics.push(latency);
// 直近100件を保持
if (this.metrics.length > 100) {
this.metrics.shift();
}
// 平均遅延を計算
const avg = this.metrics.reduce((a, b) => a + b, 0) / this.metrics.length;
console.log(`📊 平均遅延: ${avg.toFixed(2)}ms`);
}
}私のテスト環境での実測値の目安:
- エンドツーエンド遅延:300-500ms(ネットワーク環境に依存)
- 初回レスポンス時間:200-400ms
- 連続対話時遅延:150-300ms
もし遅延がこれより大幅に大きい場合は、以下の項目を確認してください。
- WebSocket 接続は HTTPS/WSS 経由か?(HTTP は追加コストが発生します)
- サーバーの配置場所は?(Google のデータセンターに近いほど有利です)
- VAD 検知に時間がかかりすぎていないか?(フレーム長を短くしてみてください)
- フロントエンドの再生バッファが大きすぎないか?
また、Chrome などのブラウザはユーザーインタラクションなしでの音声再生を制限しているため、ページ内に「対話を開始」といったボタンを用意し、ユーザーのクリックをトリガーにする必要があります。
まとめ
これで、Gemini Live API を使用したアプリケーション開発の全体像を把握できました。コンセプトの理解からアーキテクチャ設計、WebSocket 接続、音声収集、VAD 検知、割り込み機能、そしてパフォーマンス最適化まで、私が実際に経験した「落とし穴」を含めて解説しました。
リアルタイム音声対話の分野は急速に進化しており、Gemini Live API 自体もアップデートが続いています。しかし、ここで紹介した基礎アーキテクチャは十分に通用するものです。私のプロジェクトでも数ヶ月間安定して稼働しています。
開発中に何か問題に直面した際は、ぜひ周囲のコミュニティなどで交流を深めてみてください。一人で悩むよりも、議論し合う方が技術の進歩は格段に早くなります。
FAQ
なぜフロントエンドとバックエンドを分離したアーキテクチャが必要なのですか?
サンプリングレートに 16kHz を選ぶ理由は何ですか?
VAD の aggressiveness パラメータを調整する基準は?
Barge-in(割り込み)機能の実装には特別な開発が必要ですか?
5 min read · 公開日: 2026年2月27日 · 更新日: 2026年3月18日
関連記事
OpenClaw 2026.3 実践アドバンス:新バージョンのコア機能とベストプラクティス

OpenClaw 2026.3 実践アドバンス:新バージョンのコア機能とベストプラクティス
OpenClaw 実践完全マニュアル:入門から精通まで

OpenClaw 実践完全マニュアル:入門から精通まで
単一モデルの囚人にならない:Antigravity で Gemini 3、Claude 4.5、GPT-OSS を柔軟に使い分ける方法

コメント
GitHubアカウントでログインしてコメントできます