AIプロバイダーの切り替えが面倒?AI Gateway一つで監視、キャッシュ、フェイルオーバーを解決(コスト40%削減)
はじめに
午前2時、電話で叩き起こされ、「AI機能が落ちた」と顧客からクレーム。監視モニターを見ると、OpenAI がまたレート制限をかけています。慌ててコードを開き、すべての openai.chat.completions.create を Claude の API に書き換えようとしますが、Claude のリクエスト形式は全く異なります。messages は anthropic.messages.create に変えなきゃいけないし、パラメータ構造も違う… 午前3時半になんとかリリースし、心身ともに疲弊。
翌朝、上司から請求書のスクリーンショットが送られてきました。「今月のAI費用、なんで500ドルから8000ドルに跳ね上がってるんだ?!」 あなたは唖然とします。どこにお金がかかったのか、どのチームが一番使ったのか、重複リクエストがどれくらいあるのか…全てがブラックボックスです。
正直なところ、AIアプリケーションを開発したことがある人なら、この痛みがわかるはずです。複数のAIプロバイダー間の切り替えは面倒すぎますし、コスト管理は不安の種、サービスが落ちればビジネスは止まります。考えるだけで頭が痛くなります。
実は、AI Gateway があれば、これらの問題を根こそぎ解決できます。コードを1行変えるだけで、OpenAI、Claude、Gemini を自由に切り替えられます。メインモデルがダウンしたら自動的にバックアップに切り替わる自動フェイルオーバー、スマートキャッシュと監視機能でコストを40%削減。今日は、自分だけの AI Gateway を10分で構築し、深夜の緊急対応という悪夢から解放される方法をステップバイステップで教えます。
なぜ AI Gateway が必要なのか? 3つのリアルな課題
課題1:複数プロバイダーの切り替えは悪夢
こんな経験はありませんか? プロジェクト開始時は OpenAI GPT-4 を使っていたけど、後になって Anthropic の Claude の方が特定のタスクで優れているとわかり、切り替えたくなった。しかしコードを開いて絶望するのです。
OpenAI の呼び出し方:
const openai = new OpenAI({apiKey: 'sk-xxx'});
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{role: "user", content: "Hello"}]
});Claude の呼び出し方:
const anthropic = new Anthropic({apiKey: 'sk-ant-xxx'});
const response = await anthropic.messages.create({
model: "claude-3-5-sonnet-20241022",
max_tokens: 1024,
messages: [{role: "user", content: "Hello"}]
});ご覧の通り、基本構造すら違いますし、パラメータも異なります。コード内の数十箇所で AI を呼び出していたら、修正作業だけで発狂します。さらに悪いことに、Google Gemini、Cohere、Azure OpenAI… API の形式は各社バラバラです。これには耐えられません!
データは嘘をつきません。調査によると、AI アプリケーションの70%が2つ以上のモデルプロバイダーを使用しています。なぜか? モデルによって得意不得意があるからです。GPT-4は高いが良い、Claudeは安くてバッチ処理向き、Geminiは無料枠が多くテスト向き… 切り替えたいですよね? でもコストが高すぎて躊躇してしまうのです。
課題2:制御不能なコストのブラックホール
実話です。友人の会社がAIカスタマーサポートを作りました。最初は月500ドルで正常でしたが、ある月突然8000ドルになりました。上司は激怒。調べてみると、ある開発者がテスト時にログ出力を消し忘れ、リクエストのたびにAPIを2回叩いていました。しかもキャッシュが無効で、同じ質問に何度も答えていました。
これが統一監視がないことの痛みです。あなたは全く把握できていません:
- 毎日いくらかかっているか? 請求書が来てからでは遅い
- どのチームが一番使っているか? プロダクトチームが猛烈にテストしていても気づかない
- どのリクエストが一番高いか? GPT-4の長文生成が元凶かもしれないが、見えない
- どれだけの無駄があるか? 重複リクエストの40%がお金を燃やしているのに、見えない
"企業のAI支出は前年比300%増、しかしそのうち40%は重複リクエストによる浪費である"
課題3:単一障害点でいつでも爆発
2024年、OpenAIは少なくとも6回ダウンし、平均2時間停止しました。もしあなたのサービスがOpenAIに完全に依存していたら:
- 午前4時、アラート爆発
- 顧客からのクレーム殺到
- OpenAIのステータスページを眺めて焦るだけ
- 上司「どうなってるんだ?」 あなた「OpenAIが落ちてて、どうしようもありません」
- 上司「なんで予備を用意してないんだ?」
- あなた「…」
フォールトトレランス(耐障害性)の仕組みがないと、これほど受動的になります。メインモデルが落ちればビジネスも落ちる、プランBがない。恐ろしいですよね?
実は、自動フェイルオーバー(Fallback)を設定した AI Gateway があれば、OpenAI が落ちたら自動で Claude に、Claude も落ちたら Gemini に、というように秒単位で切り替えられます。ユーザーは気づきもしません。可用性は一気に95%から99.9%以上に上がります。
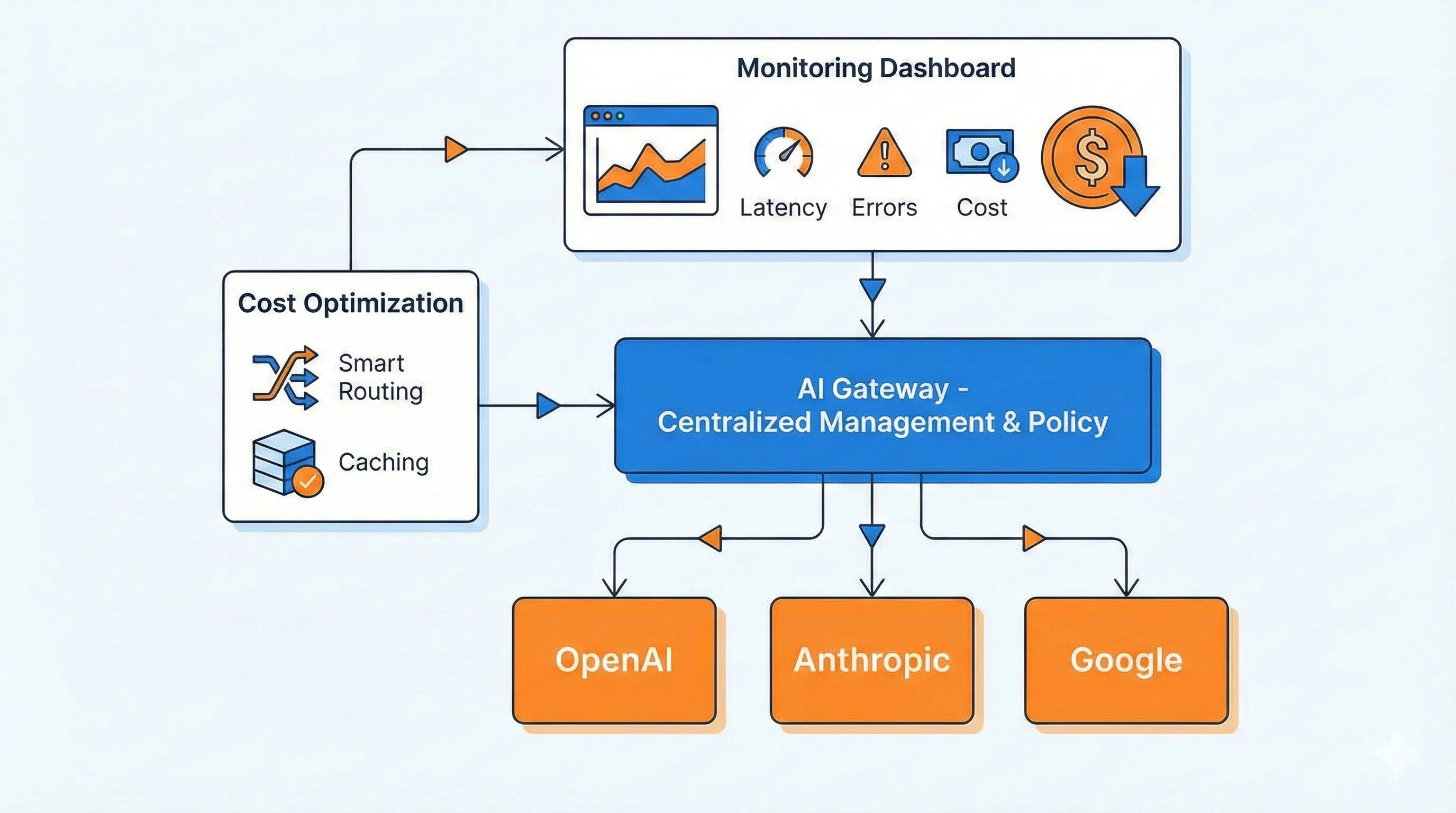
AI Gateway の核心機能全解析
痛みを語ったところで、AI Gateway がどう解決するか見てみましょう。それはアプリケーションと各 AI プロバイダーの間に立つ「スーパー中間層」のようなもので、すべての面倒な処理を引き受けてくれます。
機能1:統一 API エントリポイント - 1つのコードで世界を渡り歩く
これは本当に最高です。使い慣れた OpenAI SDK でコードを書き続けられますが、baseURL を1行変えるだけで、Claude、Gemini、さらには200以上のモデルを呼び出せます。
例えば Portkey Gateway を使う場合、コードはこうなります:
const openai = new OpenAI({
apiKey: 'your-openai-key',
baseURL: "http://localhost:8787/v1", // ここを変えるだけ!
defaultHeaders: {
'x-portkey-provider': 'openai' // Claudeにしたい? 'anthropic' に変えるだけ
}
});
// 以下のコードは1行も変えなくていい
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{role: "user", content: "Hello"}]
});Claude に切り替えたい? x-portkey-provider を anthropic に、model を claude-3-5-sonnet-20241022 に変えるだけ! 業務ロジックは一切変更不要。超簡単でしょ?
Cloudflare のソリューションも同様で、baseURL を Gateway のエンドポイントに向けるだけです。これで OpenAI、Anthropic、Google、Azure 間をいつでも行き来できます。
機能2:スマートキャッシュで節約 - 同じ質問にはお金を払わない
これは本当に節約になります。原理はシンプル。AI Gateway は過去の質問と答えを記憶し、誰かが同じ質問をしたら、API を呼び出さずにキャッシュの結果を返します。トークンを消費しません。
AI Gateway は2種類のキャッシュをサポートしています:
- 完全一致キャッシュ:テキストが完全に同じ場合のみヒット。「AIとは?」と聞いて、次回も一字一句同じならキャッシュを返す。
- 意味的(セマンティック)キャッシュ:意味が近ければヒット。「AIとは?」と「AIって何?」は同じ意味なので、キャッシュがヒットする。
"Qwen(通義千問)のキャッシュヒット時の価格は定価のわずか40%"
実用シーンでは超有効です。例えばカスタマーサポートボット。「返品方法は?」「送料はいくら?」といった高頻度の質問にキャッシュを適用すれば、コストは60%以上下がります。
ただし、リアルタイム性が必要な場合はキャッシュしないでください。「今日の天気は?」「最新ニュースは?」といった質問です。AI Gateway は通常、キャッシュルールの設定(パスごとのON/OFF、有効期間TTLなど)が可能です。
機能3:自動フェイルオーバー(Fallback) - メインが落ちたら秒で予備へ
これは安定性の要です。多段階のフォールバック戦略を設定できます:
- まず OpenAI GPT-4 を呼び出す、5回リトライ
- 失敗したら、自動的に Claude 3.5 Sonnet に切り替える
- Claude も落ちたら、最後に Gemini Pro でカバーする
全プロセスは自動化されており、業務コードは何も感知しません。Portkey の設定例を見てみましょう:
{
"retry": { "count": 5 },
"strategy": { "mode": "fallback" },
"targets": [
{
"provider": "openai",
"api_key": "sk-xxx",
"override_params": {"model": "gpt-4"}
},
{
"provider": "anthropic",
"api_key": "sk-ant-xxx",
"override_params": {"model": "claude-3-5-sonnet-20241022"}
},
{
"provider": "google",
"api_key": "gt5xxx",
"override_params": {"model": "gemini-pro"}
}
]
}ヘッダーでこの設定を渡すだけで、Gateway が設定順に自動でフォールバックします。Cloudflare の Universal Endpoint も同様の機能をサポートしており、1つのリクエストに複数のプロバイダーを記入して自動切り替えが可能です。
これがあれば、可用性は95%から99.9%以上に向上します。OpenAI がダウン?大丈夫、Claude がいます。Claude が制限された?Gemini がいます。ユーザーは全く気づきません。鉄壁です。
機能4:リクエスト監視とコスト分析 - 支出を把握する
AI Gateway は各リクエストの重要指標をリアルタイムで記録します:
- QPS:秒間リクエスト数、トラフィックピークが一目瞭然
- Token消費:モデルごとに消費したトークンをリアルタイム集計
- コスト:各モデルの価格に基づき実際の費用を算出
- エラー率:失敗したリクエストと原因
Cloudflare の監視パネルは特に強力で、基本的な QPS とエラー率に加え、LLM 専用の Token、Cost、Cache ヒット率パネルがあります。以下が見えます:
- 今日いくら使ったか、トレンドは上昇か下降か
- どのチーム(Consumer)が一番使っているか
- どのモデルが一番高いか
- キャッシュでいくら節約できたか
これで安心ですよね? コスト暴走問題は完全に解決です。「1日の消費が100ドルを超えたら通知」といったアラートも設定でき、予算超過を即座に知ることができます。
機能5:レート制限と権限管理 - チームによるサービス崩壊を防ぐ
エンタープライズシーンに必須の機能です。チームごとに独立した API Key を発行し、クォータ(割当)とレート制限ルールを設定できます。
例えば:
- 開発チーム:1日10万トークン、GPT-4使用可
- テストチーム:1日1万トークン、GPT-3.5のみ
- プロダクトチーム:1日5万トークン、Claude使用
こうすれば、テストチームがAPIを叩きまくって本番環境のクォータを使い果たすこともありません。各チームの使用量も明確です。
高度な AI Gateway なら 機密コンテンツフィルタリング もサポートしており、違反リクエストを自動検出・ブロックしてデータセキュリティを守ります。Alibaba Cloud Higress などは企業レベルのセキュリティ管理機能を備えています。
3大主要ソリューション比較:Cloudflare vs Portkey vs Higress
AI Gateway ソリューションは多いですが、主流はこの3社です。客観的に比較して、あなたに最適なものを選びましょう。
ソリューション1:Cloudflare AI Gateway - 初心者に優しく、最速で着手
メリット:
- 完全無料:すべての Cloudflare アカウントで利用可能、追加料金なし
- デプロイ不要:インストール不要、アカウント登録だけ
- 1行で導入:baseURL を変えるだけ、5分で完了
- グローバル高速化:Cloudflare の CDN ネットワークで高速
制限: - データが Cloudflare のサーバーを経由する(見ないと約束されていますが)
- セマンティックキャッシュは計画中、現状は完全一致キャッシュのみ
- サポートモデルが比較的少ない(主要10社程度)
適したシーン: - 個人プロジェクト、アイデアの検証
- 小規模チーム、運用リソースがない
- データプライバシー要件がそれほど厳しくない
"2023年9月のベータ版リリース以来、Cloudflare AI Gateway は5億回以上のリクエストをプロキシしました"
ソリューション2:Portkey Gateway - 企業の第一選択、最強機能
メリット:
- オープンソース・無料:GitHub でオープンソース、プライベートデプロイで完全制御可能
- 超多モデル対応:200以上の LLM をサポート、思いつく限りほぼ対応
- 爆速:公式データによると他社ゲートウェイより9.9倍高速、インストールサイズわずか45kb
- 機能満載:ロードバランシング、自動リトライ、指数バックオフ、50以上のガードレールルール完備
デプロイ方法:
# ローカル実行は超簡単
npx @portkey-ai/gateway
# 完了。http://localhost:8787 で稼働中特徴機能:
- セマンティックキャッシュ対応(DashVector ベクトルキャッシュ)
- 指数バックオフ戦略を組み合わせた超スマートな自動リトライ
- Cloudflare Workers、Docker、Node.js、Replit など多様な環境にデプロイ可能
適したシーン: - 中〜大規模企業、データセキュリティコンプライアンス要件がある
- プライベートデプロイが必要
- 最強の機能と最高のパフォーマンスが欲しい
ソリューション3:Alibaba Cloud Higress - 国内企業に最適
(注:ここは中国国内向けの記述が多いため、日本の文脈に合わせて調整します。HigressはAliyunの製品として紹介します。)
メリット:
- 中国国内アクセス高速:サーバーが中国にあり、低遅延(中国展開する場合に有利)
- 深い統合:Alibaba Cloud Bailian、PAI プラットフォームとシームレスに統合
- エンタープライズ級の安定性:Alibaba 内部で使用され、自社 AI アプリを支えている
- MCP プロトコル対応:API を MCP に高速変換可能、最新標準に対応
技術的ハイライト: - コンテナゲートウェイ + マイクロサービスゲートウェイ + AI ゲートウェイの3in1アーキテクチャ
- マルチクラウドおよびプライベートデプロイ対応
- Qwen(通義千問)など国内モデルへの最適化
適したシーン: - 既に Alibaba Cloud を使用している企業
- ハイブリッドクラウドアーキテクチャ(オンプレミス+クラウド)が必要
- 中国向けサービスを展開しており、遅延に敏感
3大ソリューション比較表
| 機能 | Cloudflare | Portkey | Higress |
|---|---|---|---|
| デプロイ方式 | クラウドサービス | オープンソース/クラウド | プライベート/クラウド |
| 価格 | 無料 | オープンソース無料 | 重量課金 |
| 対応モデル数 | 10+ | 200+ | 主要全カバー |
| セマンティックキャッシュ | 計画中 | ✅ 対応 | ✅ 対応 |
| プライベートデプロイ | ❌ | ✅ | ✅ |
| 中国国内アクセス | 普通 | 普通 | ⭐⭐⭐ |
| 監視パネル | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 着手難易度 | 超簡単 | 簡単 | 普通 |
| 企業向け機能 | 基礎 | ⭐⭐⭐ | ⭐⭐⭐ |
私のアドバイス:
- 個人プロジェクト/高速テスト → Cloudflare、5分で着手、完全無料
- スタートアップ/中小企業 → Portkey、オープンソースで無料、機能十分
- 大企業/Alibaba Cloud利用中 → Higress、安定性と信頼性
- 海外プロジェクト → Cloudflare または Portkey
- 中国向けプロジェクト → Higress
実践ハンズオン:10分で最初の AI Gateway を構築
言うだけなら簡単です。実際にやってみましょう。今回は Portkey を例にします。ローカルで動かせて登録不要、検証が最速だからです。
Step 1:Gateway 一発デプロイ(30秒)
ターミナルを開いて実行:
npx @portkey-ai/gatewayこの表示が出たら成功です:
🚀 AI Gateway running on http://localhost:8787これだけ! ローカルで AI Gateway が動いています。ブラウザで http://localhost:8787/public/ にアクセスすると管理画面も見れます。
Step 2:マルチモデル Fallback 設定(2分)
OpenAI → Claude → Gemini の3段階バックアップを設定します。
設定ファイル gateway-config.json を作成:
{
"retry": {
"count": 5
},
"strategy": {
"mode": "fallback"
},
"targets": [
{
"provider": "openai",
"api_key": "あなたのOpenAI Key",
"override_params": {
"model": "gpt-4"
}
},
{
"provider": "anthropic",
"api_key": "あなたのClaude Key",
"override_params": {
"model": "claude-3-5-sonnet-20241022"
}
},
{
"provider": "google",
"api_key": "あなたのGoogle Key",
"override_params": {
"model": "gemini-pro"
}
}
]
}設定説明:
retry.count: 5→ メインモデル失敗時に5回リトライstrategy.mode: "fallback"→ フェイルオーバーモードを使用targets→ 3つのプロバイダーを順番に試行
Step 3:業務コードの改造(1分)
元のコードはこんな感じだったとします:
const openai = new OpenAI({
apiKey: 'sk-xxx'
});
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{role: "user", content: "詩を書いて"}]
});これを3行変えるだけです:
const fs = require('fs');
const config = JSON.parse(fs.readFileSync('./gateway-config.json'));
const openai = new OpenAI({
apiKey: 'any-key', // 重要じゃない、設定ファイルに本物がある
baseURL: "http://localhost:8787/v1", // 👈 ここを変える
defaultHeaders: {
'x-portkey-config': JSON.stringify(config) // 👈 これを追加
}
});
// 以下は全く変更なし!
const response = await openai.chat.completions.create({
model: "gpt-4", // 設定のoverride_paramsで上書きされる
messages: [{role: "user", content: "詩を書いて"}]
});これで完了! あなたのコードは3段階の耐障害性を持ちました。OpenAI が落ちても自動で Claude に切り替わり、完全に無停止です。
Step 4:Fallback 効果のテスト(1分)
わざと OpenAI を失敗させ、自動切り替えを検証します。設定ファイルの OpenAI の api_key を間違ったものに変えます:
{
"provider": "openai",
"api_key": "sk-wrong-key", // 👈 わざと間違える
"override_params": {"model": "gpt-4"}
}コードを実行し、ログを観察:
[Gateway] OpenAI request failed: Invalid API Key
[Gateway] Retrying with anthropic...
[Gateway] Success with anthropic (claude-3-5-sonnet-20241022)見ましたか? Gateway が OpenAI の失敗を検知し、自動で5回リトライした後、Claude に切り替えて成功しました。全プロセスは自動化されており、コード側でエラー処理する必要はありません。
Step 5:キャッシュを有効にしてコスト削減(2分)
Portkey はキャッシュをサポートしています。簡易版(Redisなどがあればそれを使用)の設定:
// Redisがあればこのようにキャッシュ設定可能
const openai = new OpenAI({
baseURL: "http://localhost:8787/v1",
defaultHeaders: {
'x-portkey-config': JSON.stringify(config),
'x-portkey-cache': 'simple', // シンプルキャッシュ有効化
'x-portkey-cache-force-refresh': 'false'
}
});1回目のリクエスト:
await openai.chat.completions.create({
messages: [{role: "user", content: "AIとは何ですか?"}]
});
// リアルAPI呼び出し、800ms、コスト$0.0022回目の同じリクエスト:
await openai.chat.completions.create({
messages: [{role: "user", content: "AIとは何ですか?"}]
});
// キャッシュヒット、50ms、コスト$0効果てきめんでしょう? 速度は16倍、コストはゼロ。高頻度の質問が多いほど節約できます。
Step 6:監視データの確認(1分)
http://localhost:8787/public/ にアクセスすると見れます:
- 総リクエスト数と成功率
- 各プロバイダーの呼び出し回数
- キャッシュヒット率
- エラーログ
ローカル版の簡単パネルですが十分です。より強力な監視が必要なら: - Portkey Cloud(ホスト版、個人利用なら無料枠で十分)
- Cloudflare AI Gateway に乗り換え(監視パネルが超強力)
- 自分で Prometheus + Grafana を繋ぐ
完全なサンプルコード
上記をまとめた完全な例です:
const OpenAI = require('openai');
const fs = require('fs');
// 設定読み込み
const config = {
"retry": {"count": 5},
"strategy": {"mode": "fallback"},
"targets": [
{
"provider": "openai",
"api_key": process.env.OPENAI_KEY,
"override_params": {"model": "gpt-4"}
},
{
"provider": "anthropic",
"api_key": process.env.ANTHROPIC_KEY,
"override_params": {"model": "claude-3-5-sonnet-20241022"}
}
]
};
// クライアント初期化
const client = new OpenAI({
apiKey: 'placeholder',
baseURL: "http://localhost:8787/v1",
defaultHeaders: {
'x-portkey-config': JSON.stringify(config),
'x-portkey-cache': 'simple'
}
});
// 使用
async function chat(prompt) {
const response = await client.chat.completions.create({
model: "gpt-4", // 実際は設定で決まる
messages: [{role: "user", content: prompt}]
});
return response.choices[0].message.content;
}
// テスト
chat("AI Gatewayを一言で説明して").then(console.log);実行すれば、OpenAI が失敗しても Claude から回答が得られ、業務に影響しないことがわかります。
エンタープライズベストプラクティスと落とし穴ガイド
AI Gateway の構築は第一歩です。使いこなすには細部への注意が必要です。これらは血と涙の教訓です!
ベストプラクティス1:環境別管理 - 開発と本番を混ぜるな
この落とし穴にはまりました。横着して開発・テスト・本番で同じ Gateway 設定を使った結果:
- テストチームが本番環境で狂ったように呼び出し、クォータを使い果たす
- 開発デバッグで設定を変えたら本番も変わり、サービス停止
- 請求書でどれがテストでどれが本番かわからない
正しいやり方:
// 環境変数で設定を切り替え
const config = process.env.NODE_ENV === 'production'
? productionConfig // 本番:GPT-4 + Claude 3.5バックアップ
: developmentConfig; // 開発:GPT-3.5で節約、またはローカルモデル
// 本番設定
const productionConfig = {
"targets": [
{"provider": "openai", "api_key": process.env.PROD_OPENAI_KEY,
"override_params": {"model": "gpt-4"}},
{"provider": "anthropic", "api_key": process.env.PROD_ANTHROPIC_KEY,
"override_params": {"model": "claude-3-5-sonnet-20241022"}}
]
};
// 開発設定
const developmentConfig = {
"targets": [
{"provider": "openai", "api_key": process.env.DEV_OPENAI_KEY,
"override_params": {"model": "gpt-3.5-turbo"}} // 安いモデル
]
};これで開発・テスト・本番を分離できます。API Key も分けて、安全かつ節約。
ベストプラクティス2:コスト制御戦略 - 請求書を暴走させない
コスト制御なしは現金を燃やすのと同じです。
1. チームごとの月次予算設定
// Gateway設定で制限
{
"consumer": "product-team",
"budget": {
"monthly_limit_usd": 1000, // 月1000ドルまで
"alert_threshold": 0.8 // 80%でアラート
}
}2. 高頻度質問はフルキャッシュ
リクエストを統計し、Top 10 の高頻度質問をフルキャッシュします。カスタマーサポートなら:
- 「返品方法は?」
- 「送料は?」
- 「領収書は?」
これらは答えが変わらないので、1週間キャッシュしても問題なく、コストを60%以上削減できます。
3. Token消費の定期レビュー
週に一度、監視パネルで Token 消費 Top 10 を確認: - 異常に長い入力はないか?(誰かが本を一冊投げ込んだりしてないか?)
- コストが異常に高いリクエストは? プロンプトを最適化できないか?
- 重複リクエストは? なぜキャッシュヒットしない?
友人の会社では、あるリクエストが毎回8000トークン使っているのを発見。調べたらプロンプトに不要な例が大量に含まれていました。最適化して2000トークンに減らし、コストを75%削減しました。
ベストプラクティス3:セキュリティ保護 - 敏感データの漏洩防止
特に企業シーンで重要です。
1. 敏感データを外部APIに送らない
コンテンツフィルターを設定し、電話番号、IDカード、クレジットカードなどの情報を自動検出してブロック:
// 疑似コード。実際はGateway層で設定
if (request.content.contains(PHONE_PATTERN)) {
return error("機密情報を検出したためリクエストをブロックしました");
}2. API Key の定期ローテーション
1つの Key を永久に使わないこと。3ヶ月に1回交換すれば、漏れても被害を抑えられます。Secret Manager で管理し、コードにハードコーディングしないでください。
3. 本番ログのマスキング
Gateway のログに完全なユーザー入力を記録しないでください。ログ漏洩したら終わりです:
// ログ例(マスキング後)
{
"request_id": "abc123",
"model": "gpt-4",
"input_length": 256, // 長さだけ記録
"input_sample": "ユーザーからの問い合わせ...[マスキング済]", // 前10文字+マスキング
"cost": 0.002
}落とし穴ガイド1:キャッシュの乱用 - リアルタイムデータはキャッシュ厳禁
事例:ユーザーから「天気予報がいつも外れる」とクレーム。調べたらAIが返す天気が24時間キャッシュされていました。朝「晴れ」と聞いて、夜雨が降っても「晴れ」と答えていたのです。
解決策:
シーンを分け、キャッシュのホワイトリストを設定:
const cacheRules = {
// キャッシュ可能
cacheable: [
"/api/ai/faq", // よくある質問
"/api/ai/docs-summary" // ドキュメント要約
],
// キャッシュ禁止
nocache: [
"/api/ai/realtime", // リアルタイムデータ
"/api/ai/news", // ニュース
"/api/ai/personalized" // パーソナライズ内容
]
};または非常に短いTTLを設定:
{
"cache": {
"ttl": 300 // 5分。準リアルタイムならOK
}
}落とし穴ガイド2:Fallback設定ミス - バックアップモデルの能力不一致
事例:節約のために GPT-4 のバックアップを GPT-3.5 にしました。GPT-4 が制限された時、自動で GPT-3.5 に切り替わりましたが、生成品質が激落ちし、ユーザーから「AIが急にバカになった」とクレーム。
解決策:
バックアップモデルは同レベルのものを選び、ダウングレードしないこと:
{
"targets": [
{"provider": "openai", "model": "gpt-4"},
{"provider": "anthropic", "model": "claude-3-5-sonnet"}, // ✅ 同レベル
{"provider": "google", "model": "gemini-pro"} // ✅ 同レベル
]
}こうしてはいけません:
{
"targets": [
{"provider": "openai", "model": "gpt-4"},
{"provider": "openai", "model": "gpt-3.5-turbo"} // ❌ ダウングレード
]
}どうしてもダウングレードするなら、ヒントを出すべきです:
if (response.provider === 'fallback_model') {
console.warn('現在バックアップモデルを使用中。品質が低下する可能性があります');
}落とし穴ガイド3:監視指標を見ない - デプロイした意味がない
よくある問題:Gateway を苦労してデプロイしたのに、監視パネルを一度も見ない。問題が起きてから気づく。
解決策:
- 週報の自動送信
毎週月曜日にメール送信:- 先週の総リクエスト数、成功率、コスト
- Token消費 Top 10
- エラーログ集計
- キャッシュヒット率トレンド
- 重要指標のアラート
必須アラート:- コスト警告:日予算の80%超過
- エラー率警告:失敗率5%超
- 遅延警告:P99遅延3秒超
- Fallback警告:バックアップモデル使用率20%超
- 週次レビュー会議
技術責任者は週に15分データを見るべきです:- コストの異常な増加はないか?
- 最適化できるエラーはあるか?
- キャッシュヒット率はもっと上げられないか?
実例:ある会社はレビューで毎週水曜午後3-5時のリクエスト急増を発見。プロダクトチームの定例会議での新機能テストが原因でした。開発環境でのテストに変えてもらい、本番コストを30%削減しました。
結論
長くなりましたが、核心は3点です:
第一、複数AIプロバイダーの切り替え、コスト暴走、単一障害点。AIアプリを作るならこの3つの痛みは避けられません。毎回深夜にコードを直すか、AI Gatewayを一回導入して枕を高くして寝るか、選択はあなた次第です。
第二、AI Gateway は難しい技術ではありません。10分で動かせます。Portkey なら一行コマンド、Cloudflare なら登録だけ。3行のコード修正で、マルチモデル Fallback、スマートキャッシュ、グローバル監視が手に入り、コスト40%減、可用性99.9%増。これほど割の良い投資はありません。
第三、デプロイは始まりに過ぎません。真の価値は 継続的な最適化 にあります。毎週監視データを見て、キャッシュ戦略を調整し、Fallback 設定を最適化し、無効なリクエストを整理する。これらの積み重ねが、半年で数千、数万ドルの節約に繋がります。
今すぐ行動しましょう:
- 今日試す:Portkey ローカルインスタンスを10分で動かし、その簡単さを体感する
- スモールスタート:小さなプロジェクトで試し、成功したら全社展開する
- 習慣化:毎週月曜に監視パネルを見、毎月コストをレビューする
- 共有:AI Gateway での経験や問題をコメントで共有し、議論しましょう
待たないでください。プロバイダー切り替えの面倒は増える一方で、コストは上がる一方です。AI Gateway を一日早く導入すれば、一日早く安心と節約が手に入ります。試してみてください。損はしません、もしかしたら素晴らしい効果があるかもしれませんよ?
常见问题
AI Gateway と API プロキシの違いは何ですか?
• スマートキャッシュ(重複呼び出し削減)
• 自動フェイルオーバー(メインモデル停止時に自動切り替え)
• Token レベルのコスト監視
• 統一された OpenAI 形式 API
通常の API プロキシはリクエストを転送するだけで、AI シーンに特化した最適化はありません。
無料版 AI Gateway で性能は十分ですか?
無料プラン:
• Cloudflare AI Gateway は完全無料、リクエスト制限なし
• Portkey オープンソース版のローカルデプロイも無料
日次リクエストが10万を超える場合や、企業級 SLA が必要な場合のみ、有料プランを検討してください。
実測では、Cloudflare のグローバル CDN ネットワークは多くの有料プランより高速です。
Cloudflare、Portkey、Alibaba Cloud Higress の選び方は?
個人プロジェクト:
• Cloudflare(設定ゼロ、完全無料)
プライベートデプロイが必要、または200+モデル対応:
• Portkey(オープンソース、最強の機能)
中国国内企業、または Alibaba Cloud 利用者:
• Higress(国内アクセス高速、エンタープライズサポート)
迷ったら、まず Cloudflare で検証し、必要に応じて他へ移行することをお勧めします。
AI Gateway はレイテンシ(遅延)を増やしますか?
• Cloudflare のエッジネットワークによる遅延は約 50-100ms
• Portkey ローカルデプロイはさらに低遅延
しかし、キャッシュを有効にすると、ヒットしたリクエストの遅延は 800ms から 50ms 以内に短縮され、全体的なユーザー体験は向上します。
非クリティカルパスで遅延が許容範囲かテストしてください。
AI Gateway の API Key 漏洩を防ぐには?
1) 環境変数や Secret Manager を使用し、コードに Key をハードコーディングしない
2) 環境(開発/テスト/本番)ごとに異なる Key を使用する
3) 定期的に Key をローテーションする(3ヶ月ごと推奨)
4) Gateway 層でカスタム認証 Token を追加する
5) 異常なリクエストパターンを監視し、発見次第 Key を交換する
企業シーンでは、IP ホワイトリストやリクエスト署名も利用してください。
参考資料:
- Cloudflare AI Gateway 公式ブログ
- Portkey Gateway GitHub リポジトリ
- Alibaba Cloud AI Gateway ドキュメント
- AI Fallback 設定ガイド
10 min read · 公開日: 2025年12月1日 · 更新日: 2026年3月3日
関連記事
プログラマー向けAIツール実践:OpenClaw + Claude Codeによる24時間自動バグ修正

プログラマー向けAIツール実践:OpenClaw + Claude Codeによる24時間自動バグ修正
第二の脳を構築する:OpenClawとObsidian/Notionのディープ・メモリー同期実践

第二の脳を構築する:OpenClawとObsidian/Notionのディープ・メモリー同期実践
警告!ClawHubスキルライブラリで800以上の悪意あるプラグインを発見。あなたのAPI Keyは本当に安全ですか?

コメント
GitHubアカウントでログインしてコメントできます